
Oprogramowanie stanowi cenne dobro, efekt końcowy setek godzin projektowania, programowania oraz testowania, dlatego ochrona oprogramowania przed złamaniem, a w efekcie przed nielegalnym użytkowaniem jest tak ważna w dzisiejszych czasach.
Celem pracy jest przedstawienie różnych metod łamania oprogramowania, z wykorzystaniem wszystkich dostępnych technik oraz nowoczesnych narzędzi, takich jak m.in. debuggery, dezasemblery oraz dekompilatory itd.
Celem końcowym pracy jest utworzenie przykładowego oprogramowania zabezpieczającego, wykorzystującego opisane metody ochrony aplikacji przed złamaniem.
W tworzeniu aplikacji został wykorzystany pakiet Microsoft Visual Studio w wersji 2003. Do analizy jakości kodu został wykorzystany pakiet Parasoft C++ Test.
Rozdział 1. Łamanie oprogramownia
1.1. Historia
Łamanie oprogramowania (ang. cracking) ma długą historię, nierozerwalnie związaną z powstaniem pierwszych komercyjnych aplikacji na takie platformy jak Apple II, Atari 800 oraz Commodore 64, gdzie twórcy oprogramowania, głównie gier, zmagali się z nielegalnym użytkowaniem swoich produktów, tworząc coraz to lepsze systemy zabezpieczeń.
Pierwsze systemy zabezpieczeń wykorzystywały w głównej mierze metody utrudniające kopiowanie fizycznych nośników danych, takich jak taśmy oraz dyskietki, poprzez specjalny zapis informacji na nośnikach, którego skopiowanie było niemożliwe lub utrudnione dla zwykłego użytkownika.
Wraz z rozwojem technologii oraz spopularyzowaniem się komputerów PC, metody bazujące na sprzętowych zabezpieczeniach zaczęły ewoluować w kierunku rozwiązań czysto programowych z wykorzystaniem najnowszych metod szyfrowania, wykrywania narzędzi służących do łamania oprogramowania oraz innowacyjnych systemów licencjonowania, bazujących najczęściej na infrastrukturze kluczy publicznych.
Rozwiązania sprzętowe są również wykorzystywane, ale w mniejszym stopniu, przykładem tutaj mogą być klucze sprzętowe (ang. dongle) oparte na interfejsach LPT oraz USB, jednak ze względu na wysokie koszty wdrożenia są stosowane głównie jako element zabezpieczenia drogich i specjalistycznych aplikacji.

1.2. Metody łamania oprogramowania
W tym podrozdziale zostaną omówione metody łamania oprogramowania oraz usuwania zabezpieczeń z aplikacji.
1.2.1. Analiza oprogramowania
Analiza oprogramowania, w tym jego zabezpieczenia, jest podstawą do wszelkich dalszych prac. Do analizy wykorzystuje się najczęściej dezasemblery (ang. disassembler), czyli programy dezasemblujące kod binarny aplikacji do kodu asemblera procesora, na jaki została skompilowana aplikacja.
W przypadku aplikacji dla systemu Windows mamy do czynienia z kodem na procesory w architekturze x86 (zarówno 32 jak i 64 bitowe). Analizę oprogramowania jako cały proces, określa się mianem inżynierii wstecznej (ang. reverse engineering).
Do najpopularniejszych aplikacji dezasemblujących obecnie należy pakiet IDA Pro, który stanowi połączenie dezasemblera oraz debuggera. IDA pozwala na dezasemblację aplikacji napisanych nie tylko dla platformy Windows (format plików PE), ale także dla platformy Linux (format plików ELF).
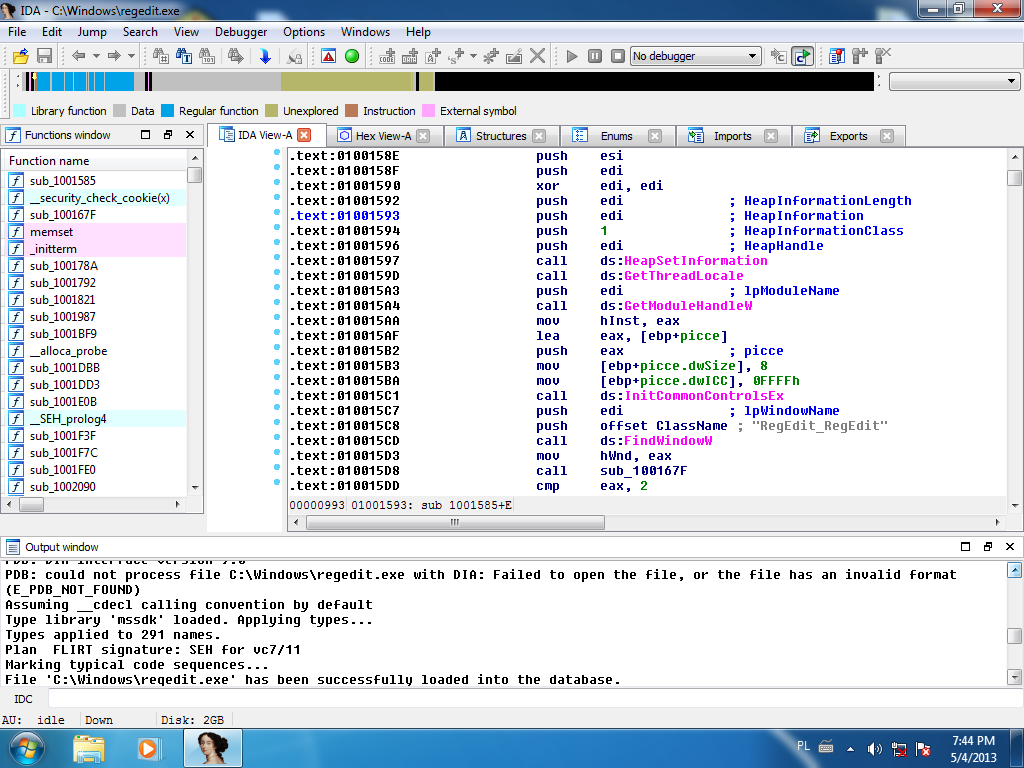
Dzięki wbudowanemu systemowi sygnatur, IDA potrafi również automatycznie rozpoznawać
popularne biblioteki wykorzystywane w aplikacjach jak np. RTL, MFC,
VCL. Metoda ta pozwala na zidentyfikowanie po sygnaturach bajtowych nazwy
większości funkcji z tych bibliotek, np. memcmp(), strlen(), dzięki czemu ułatwiona jest analiza kodu aplikacji.
IDA jest bardzo rozbudowanym oprogramowaniem i posiada wsparcie dla wtyczek rozszerzających jej możliwości, a także wbudowany własny język skryptowy, przypominający w składni język programowania C.
W sumie IDA potrafi dokonać dezasemblacji kodu skompilowanego dla ponad 50 różnych procesorów z obsługą podstawowych oraz rozszerzonych zestawów instrukcji, m.in.:
- Intel
- AMD
- ARM
- Fujitsu FR
- Hitachi HD
- Motorola
- Rockwell
- Z80
Poniżej znajduje się przykładowy kod, napisanych w języku C, który po skompilowaniu zostanie poddany dezasemblacji.
#include <stdio.h>
int main(int argc, char *argv[])
{
// wyświetl tekst na konsoli
printf("Hello World!");
// zakończ aplikację z kodem błędu 0
return 0;
}Kod został skompilowany kompilatorem LCC dla systemu Windows do pliku wykonywalnego. Po dokonaniu dezasemblacji pliku binarnego w oprogramowaniu IDA, można zobaczyć efekt kompilacji źródła w języku C do kodu asemblera x86. Poniżej przedstawiony jest fragment obrazujący skompilowaną funkcję main:
.text:0040129C main proc near ; CODE XREF: start+66p
.text:0040129C 55 push ebp
.text:0040129D 89 E5 mov ebp, esp
.text:0040129F 68 94 90 40 00 push offset aHelloWorld
.text:004012A4 E8 34 5B 00 00 call printf
.text:004012A9 59 pop ecx
.text:004012AA 31 C0 xor eax, eax
.text:004012AC 5D pop ebp
.text:004012AD C3 retn
.text:004012AD main endpKod poddany procesowi dezasemblacji nazywa się potocznie martwym
listingiem (ang. deadlisting). Można zauważyć, że zdezasemblowany fragment
zawiera takie informacje, jak nazwa sekcji pliku wykonywalnego (plik
wykonywalny zawiera różne sekcje, w których zapisywane są takie dane jak kod,
dane statyczne, zasoby etc.), w którym znalazł się wybrany fragment
kodu, w tym wypadku nazwa sekcji to .text, następnie obok kolejnych
instrukcji asemblera, wyświetlony jest ich adres w pamięci oraz kod instrukcji
zapisany w systemie szesnastkowym (tak jak jest on zapisany w
skompilowanym pliku).
Jak można zauważyć na przestawionym fragmencie kodu, do analizy oprogramowania wymagana jest dobra znajomość składni oraz instrukcji asemblera oraz podstawowa znajomość struktury plików wykonywalnych.
1.2.2. Analiza zabezpieczenia
Autorskie systemy zabezpieczeń oprogramowania wymagają najczęściej ręcznej analizy w dezasemblerze, natomiast popularność gotowych systemów zabezpieczeń przyczyniła się do powstania automatycznych narzędzi, które potrafią rozpoznać zastosowane zabezpieczenie w wybranej aplikacji.
Narzędzia takie to identyfikatory i ich działanie polega na skanowaniu plików aplikacji w poszukiwaniu znanych sygnatur binarnych najbardziej popularnych systemów zabezpieczeń.
Działanie to można przyrównać do skanerów antywirusowych, które również wykorzystują skanowanie w poszukiwaniu znanych sygnatur wirusów komputerowych.

Powyżej przedstawiony jest identyfikator PEiD, który wykrył, że plik programu został skompresowanych popularną aplikacją ASPack (kompresującą pliki wykonywalne).
1.2.3. Śledzenie działania aplikacji
Analiza oprogramowania poprzez dezasemblację nie zawsze się sprawdza, ponieważ widoczny jest tylko statyczny kod, a niejednokrotnie zaszyfrowany, dlatego obok dezasemblacji drugą najczęściej wykorzystywaną techniką pozwalającą uzyskać bardziej szczegółowe informacje jest odpluskiwanie (ang. debugging).
Odpluskiwanie aplikacji polega na uruchomieniu kodu aplikacji pod nadzorem specjalnego oprogramowania (ang. debugger) oraz śledzeniu krok po kroku, kolejno wykonywanych operacji. Technika ta wykorzystywana jest najczęściej do odnajdywania ukrytych błędów w aplikacjach.
W dzisiejszych czasach praktycznie każde zintegrowane środowisko programistyczne (ang. IDE) posiada wbudowany debugger, pozwalający na odnajdywanie kłopotliwych fragmentów kodu.
Należy tutaj zauważyć, że odpluskiwanie w takich warunkach odbywa się przy jednoczesnym dostępie do kodów źródłowych aplikacji (z opcjonalną możliwością podglądu wygenerowanego podczas kompilacji kodu asemblera), tak, że śledząc aplikację w takich warunkach widzimy kod napisany w języku wysokiego poziomu (np. C++, C#, Delphi).
Wspomniana wyżej możliwość śledzenia kodu wykonywanej aplikacji na poziomie asemblera jest natomiast najczęściej stosowaną metodą przy analizowaniu kodu łamanej aplikacji, ponieważ w większości przypadków nie ma się dostępu do kodów źródłowych.
W przeszłości najpopularniejszym narzędziem wykorzystywanym do śledzenia kodu był słynny debugger systemowy SoftICE firmy Compuware, który pozwalał na śledzenie zarówno kodu sterowników systemowych, ale także zwyczajnych aplikacji, działających w trybie użytkownika (ang. user mode).
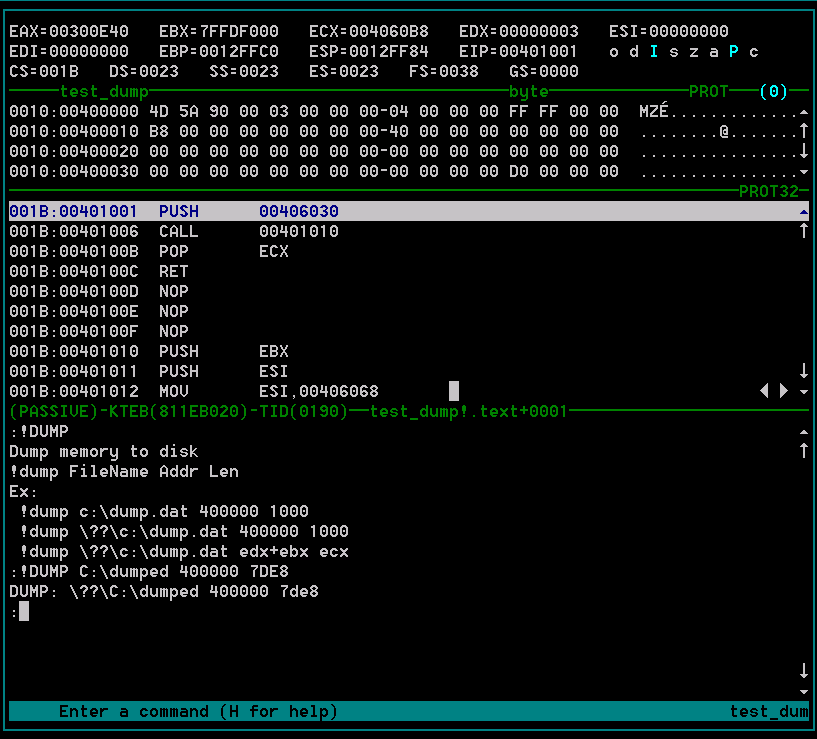
Ze względu na swoje ogromne możliwości SoftICE był głównym narzędziem wykorzystywanym do łamania aplikacji, jednak rozwój kolejnych wersji systemu Windows, a w szczególności systemów Windows XP oraz Windows Vista, spowodował coraz większe problemy z samym uruchomieniem debuggera, który miał problemy z obsługą nowych systemów operacyjnych, ale również obsługą nowych kart graficznych (SoftICE był debuggerem systemowym i wykorzystywał bezpośredni dostęp do karty graficznej). W efekcie zaistniałych problemów firma Compuware zaprzestała wypuszczanie kolejnych wersji debuggera.
Wraz z upadkiem debuggera SoftICE, zaczęły pojawiać się inne projekty, które w domyśle miały zająć jego miejsce na rynku, ale jedyny, który wybił się i stanowi standard na dzisiaj jest debugger OllyDbg autorstwa Oleha Yuschuka.
OllyDbg ewoluował z prostego narzędzia w zaawansowane oprogramowanie, które dzisiaj posiada ogromne możliwości oraz całą gamę rozszerzeń (ang. plug-ins), dzięki którym OllyDbg jest najbardziej zaawansowanych debuggerem, jaki kiedykolwiek był na rynku.
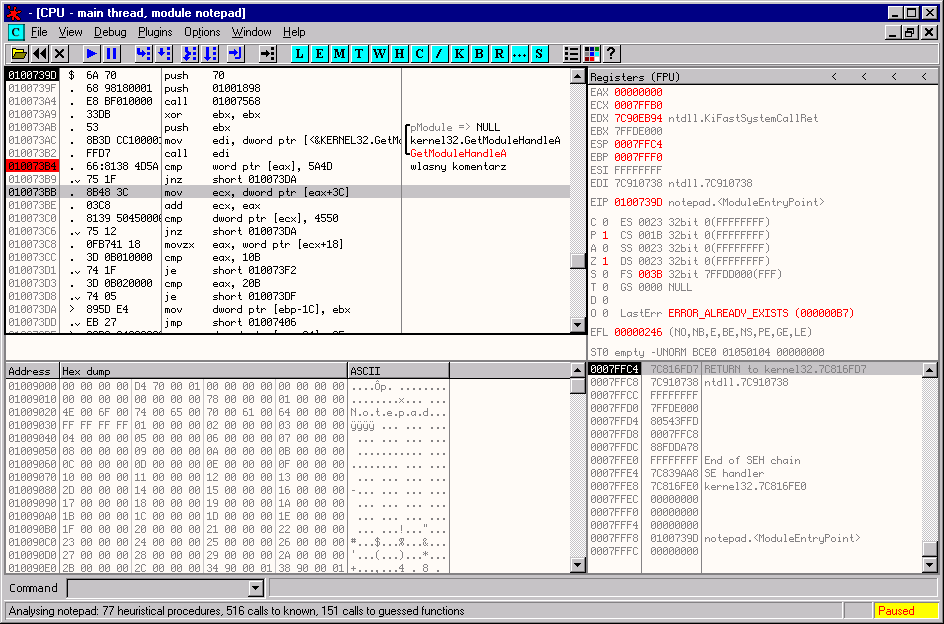
Debugger OllyDbg jest obecnie wykorzystywany przez zwykłych programistów, osoby zajmujące się analizą wirusów w firmach antywirusowych, ludzi wyszukujących luki w oprogramowaniu (wykorzystujących zmodyfikowaną wersję OllyDbg o nazwie Immunity Debugger, rozbudowaną o obsługę skryptów w języku Python) oraz osoby zajmujące się łamaniem oprogramowania.
Podstawy użytkowania Immunity Debugger
1.2.4. Śledzenie zmian w systemie
Zmiany, jakich dokonują aplikacje w systemie operacyjnym są niejednokrotnie wskazówką, ułatwiającą zrozumienie działania systemów zabezpieczających.
Najczęściej zmiany oraz dostęp do informacji zawartych w systemie plików lub w rejestrze Windows pozwalają odkryć, gdzie przykładowo zapisywane są klucze rejestrujące i inne wrażliwe dane.
Do śledzenia zmian w systemie plików, obecnie najpopularniejszą aplikacją jest FileMon (obecnie ProcMon) firmy Microsoft, który pozwala na logowanie wszelkich zmian oraz odwołań do całego systemu plików przez wszystkie uruchomione aplikacje (lub wybrane).
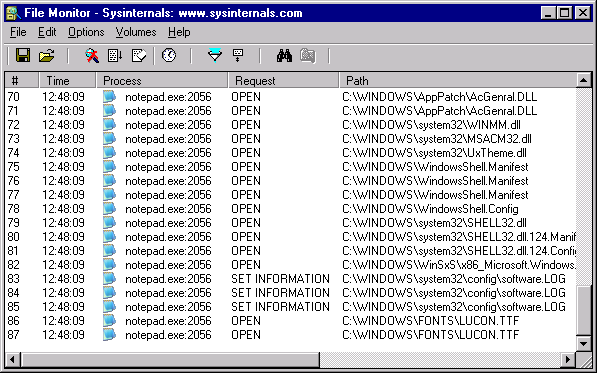
Do śledzenia zmian oraz dostępu do kluczy w rejestrze systemowym Windows, wykorzystuje się najczęściej inny program firmy Microsoft, konkretnie RegMon (obecnie ProcMon), który pozwala monitorować wszystkie lub wybrane aplikacje.
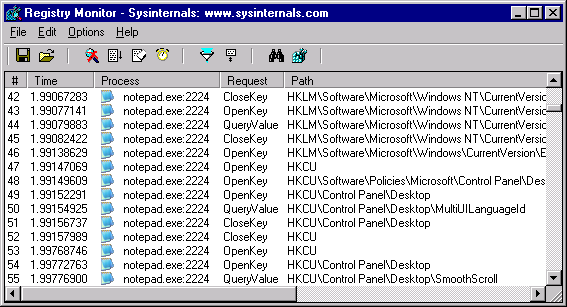
Programy takie jak FileMon oraz RegMon pozwalają jedynie na śledzenie zmian dokonywanych w systemie plików oraz rejestrze bazując na monitorowaniu całego systemu. Do tego calu wykorzystują przechwytywanie odwołań do systemu plików lub rejestru na poziomie systemu operacyjnego.
Istnieje również osobna grupa aplikacji tzw. szpiegów API (ang. API spies), które pozwalają monitorować wybraną aplikację oraz wszystkie funkcje, z których śledzona aplikacja korzysta.
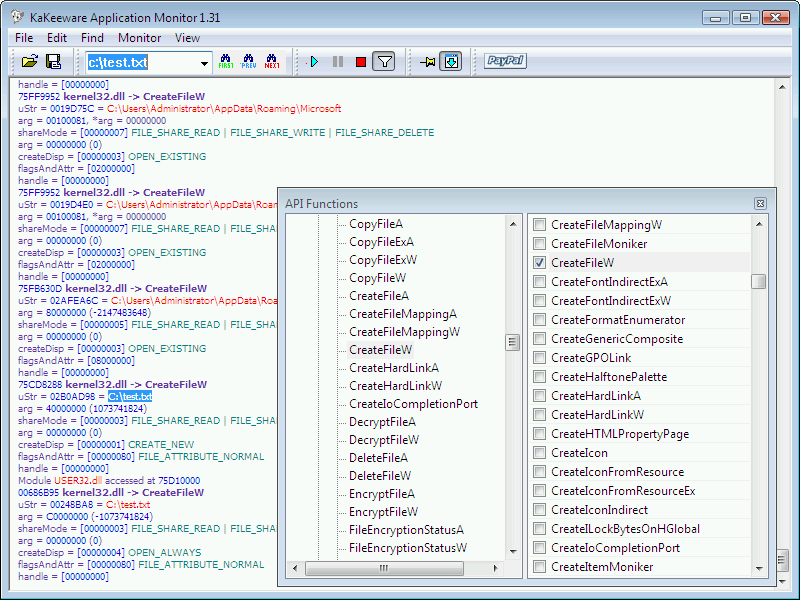
Aplikacje tego typu działają w większości poprzez przechwytywanie odwołań do systemu operacyjnego na poziomie śledzonego oprogramowania, poprzez takie techniki jak zaczepianie funkcji API (ang. API hooking) oraz wstrzykiwanie kodu (ang. code injection) odpowiedzialnego za śledzenie, bezpośrednio do aplikacji.
1.2.5. Modyfikacja plików aplikacji
Najprostszą metodą złamania oprogramowania, a w efekcie uzyskania nielegalnej kopii programu jest modyfikacja plików binarnych aplikacji. Do ręcznej modyfikacji plików binarnych wykorzystuje się hex-edytory, czyli programy, które pozwalają przeglądać (wyświetlając zawartość plików bajt po bajcie w systemie szesnastkowym) oraz edytować ich zawartość.
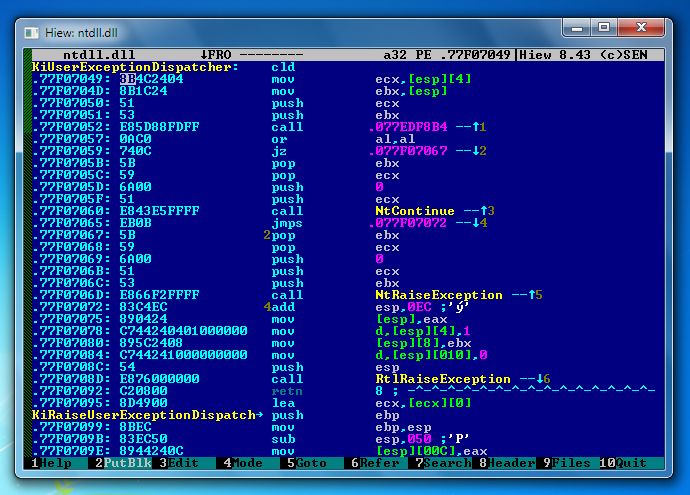
Przy łamaniu aplikacji, modyfikacje zwykle nie obejmują wielu obszarów kodu, a jedynie rozpoznane wcześniej w trakcie analizy krytyczne fragmenty, odpowiedzialne przykładowo za sprawdzenie poprawności wprowadzonego numeru seryjnego, wykorzystanego do rejestracji oprogramowania.
1.2.6. Modyfikacja pamięci aplikacji
Czasami zdarza się, że zmodyfikowanie pliku na dysku jest utrudnione lub wręcz niemożliwe np. z powodu zastosowanego zabezpieczenia aplikacji w postaci sprawdzania sum kontrolnych plików, gdzie zmiana jakichkolwiek danych w plikach aplikacji zostałaby automatycznie wykryta przez oprogramowanie i najczęściej w takich wypadkach aplikacja jest zamykana po wyświetleniu ostrzegawczego komunikatu.
Na tego typu zabezpieczenia jednak znalazły się metody, wykorzystujące fakt dostępu do pamięci aplikacji. Technika ta polega na wykryciu uruchomionej aplikacji, np. po tytule jej okienka, dzięki czemu można uzyskać dostęp do pamięci jej procesu, a następnie na nadpisaniu kodu aplikacji w pamięci z zewnętrznego programu.
Metoda ta wykorzystywana jest najczęściej do tymczasowej modyfikacji kodu uruchomionej aplikacji w celu ominięcia procedur weryfikacyjnych, np. przy wpisywaniu numeru seryjnego, gdzie po wpisaniu poprawnego numeru, aplikacja zapisuje tzw. znacznik rejestracji (flagę informującą aplikację o udanej rejestracji) do rejestru Windows.
Poniżej znajduje się przykładowy program w języku C, który po wykryciu aplikacji po nazwie okienka aplikacji, nadpisuje jeden bajt w pamięci aplikacji:
#include <windows.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
HWND hUchwytOkna = NULL;
DWORD dwProces = 0;
HANDLE hUchwytProcesu = NULL;
BYTE cBufor[3] = { 0x90 };
// znajdź okno aplikacji o podanym tytule
hUchwytOkna = FindWindow(NULL, "Aplikacja v1.0");
// sprawdź czy taka aplikacja jest uruchomiona
if (hUchwytOkna != NULL)
{
// odczytaj identyfikator procesu
// na podstawie uchwytu okienka
GetWindowThreadProcessId(hUchwytOkna, &dwProces);
// otwórz proces aplikacji
hUchwytProcesu = OpenProcess(PROCESS_ALL_ACCESS, \
1, dwProces);
// pod adresem 0x401000 w pamięci programu
// zapisz bajt z bufora cBufor
WriteProcessMemory(hUchwytProcesu, (LPVOID)0x401000, \
&cBufor[0], sizeof(cBufor), NULL);
}
else
{
printf("Nie znaleziono okna!");
}
// zakończ aplikację z kodem błędu 0
return 0;
}W powyższym przypadku zmiany dokonywane są w pamięci uruchomionej aplikacji, jednak opisana metoda nie jest skuteczna, jeśli zmiany w aplikacji mają być widoczne co uruchomienie. Do tego celu wykorzystuje się inna technikę, mianowicie tworzy się aplikację ładująca (ang. loader).
Jej zadaniem jest uruchomienie właściwej aplikacji w trybie wstrzymania (ang. suspended mode), następnie wprowadzane są zmiany do pamięci aplikacji, po czym kontynuowane jest uruchamianie, dzięki czemu już od samego początku w pamięci aplikacji będą widoczne zmiany.
Przykładowy program prezentuje opisaną technikę:
#include <windows.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
STARTUPINFO lpSi = { 0 };
PROCESS_INFORMATION lpPi = { 0 };
BYTE cBufor[1] = { 0x90 };
// zainicjalizuj strukturę STARTUPINFO
GetStartupInfo(&lpSi);
// uruchom aplikację w trybie wstrzymania
CreateProcess("C:\\aplikacja.exe", NULL, NULL, NULL, \
TRUE, CREATE_SUSPENDED, NULL, NULL, \
&lpSi, &lpPi);
// pod adresem w pamięci 0x401000
// zapisz bajty z bufora cBufor
WriteProcessMemory(lpPi.hProcess, (LPVOID)0x401000, \
&cBufor[0], sizeof(cBufor), NULL);
// przywróć wstrzymany proces do ponownego działania
ResumeThread(lpPi.hThread);
// zakończ aplikację, z kodem błędu 0
return 0;
}Metoda ta do skutecznego działania wymaga, żeby zamiast pliku aplikacji, uruchamiany był plik programu ładującego, bo jedynie to gwarantuje wprowadzenie odpowiednich zmian do pamięci aplikacji.
Czasami zdarzają się jednak sytuacje, kiedy wymagane jest zastosowanie bardziej zaawansowanych metod, przykładowo, gdy chcemy coś zmienić w pamięci aplikacji, ale pod jakimś warunkiem, wtedy statyczne zmiany dokonywane w powyższych przykładach nie są wystarczające.
W takich sytuacjach wykorzystuje się wbudowane w system Windows funkcje odpluskiwania, pomocne przy tworzeniu własnych narzędzi. Metoda ta polega na utworzeniu aplikacji przypominającej debugger, która załaduje automatycznie wskazaną aplikację oraz wykorzystując system pułapek (ang. breakpoint) będzie potrafiła zatrzymać działanie aplikacji we wskazanym miejscu oraz w zależności od zaistniałych warunków, dokonać odpowiednich zmian w pamięci aplikacji lub odczytać jakieś informacje, które dostępne są jedynie w zaistniałych warunkach (np. dane tymczasowo odszyfrowane).
Poniższy przykład prezentuje wykorzystanie opisanej techniki do uruchomienia aplikacji z zastawioną pułapką na określonym adresie kodu oraz oczekiwanie na moment, gdy aplikacja dojdzie do tego fragmentu kodu, po czym nastąpi odczytanie stanu rejestrów procesora i wartość jednego z nich zostanie skopiowana w formie tekstowej do schowka systemowego.
#include <windows.h>
#include <stdio.h>
#define BPX_AT (LPVOID)0x401361
int main(int argc, char *argv[])
{
STARTUPINFO lpSi = { 0 };
PROCESS_INFORMATION lpPi = { 0 };
DEBUG_EVENT lpDe;
CONTEXT lpCtx;
BYTE cBreakpoint = 0xCC, cOriginal;
DWORD dwWritten = 0;
DWORD dwContinueStatus = DBG_CONTINUE;
HANDLE hMem = NULL;
// zainicjalizuj strukturę STARTUPINFO
GetStartupInfo(&lpSi);
// uruchom aplikację w trybie wstrzymania
CreateProcess("C:\\aplikacja.exe", NULL, NULL, NULL, \
TRUE, DEBUG_PROCESS | DEBUG_ONLY_THIS_PROCESS | \
CREATE_SUSPENDED, NULL, NULL, &lpSi, &lpPi);
// odczytaj bajt z miejsca, gdzie wstawimy pułapkę (0xCC)
ReadProcessMemory(lpPi.hProcess, BPX_AT, &cOriginal, 1, \
&dwWritten);
// wstaw pułapkę pod wskazany adres (int 3)
WriteProcessMemory(lpPi.hProcess, BPX_AT, &cBreakpoint, 1, \
&dwWritten);
// przywróc wstrzymany proces do ponownego działania
ResumeThread(lpPi.hThread);
while (1)
{
WaitForDebugEvent(&lpDe, INFINITE);
dwContinueStatus = DBG_CONTINUE;
switch (lpDe.dwDebugEventCode)
{
case EXCEPTION_DEBUG_EVENT:
// czy to pułapka?
switch (lpDe.u.Exception.ExceptionRecord.ExceptionCode)
{
case EXCEPTION_BREAKPOINT:
// czy na naszym adresie?
if (lpDe.u.Exception.ExceptionRecord.ExceptionAddress == BPX_AT)
{
// ważne! - ustawiamy flagę, która określa
// ile danych odczytać do struktury CONTEXT,
// która zawiera informację o stanie rejestrów
// procesora w chwili zatrzymania aplikacji
// na zastawionej pułapce
lpCtx.ContextFlags = CONTEXT_ALL;
// odczytaj stan rejestrów aplikacji
GetThreadContext(lpPi.hThread, &lpCtx);
// przywróć oryginalny bajt pod adresem
// pułapki (znajduje się tam bajt 0xCC)
WriteProcessMemory(lpPi.hProcess, BPX_AT, &cOriginal, \
1, &dwWritten);
// ustaw adres powrotny dla aplikacji modyfikując
// zawartość rejestru EIP
lpCtx.Eip = (DWORD)BPX_AT;
lpCtx.ContextFlags = CONTEXT_ALL;
// ustaw kontekst z poprawnym adresem EIP
SetThreadContext(lpPi.hThread, &lpCtx);
// zapisz zawartośc rejestru EAX do systemowego schowka
if (OpenClipboard(NULL) == TRUE)
{
hMem = GlobalAlloc(GMEM_MOVEABLE | GMEM_DDESHARE, 256);
if (hMem != NULL)
{
sprintf((char *)GlobalLock(hMem), "%08X", lpCtx.Eax);
SetClipboardData(CF_TEXT, hMem);
}
CloseClipboard();
}
}
break;
}
break;
case EXIT_PROCESS_DEBUG_EVENT:
// zamknij uchwyt wątku i procesu
CloseHandle(lpPi.hThread);
CloseHandle(lpPi.hProcess);
ExitProcess(0);
}
ContinueDebugEvent(lpDe.dwProcessId, lpDe.dwThreadId, dwContinueStatus);
} // while(1)
return 0;
}Metoda ta nie jest często stosowana ze względu na stopień skomplikowania oraz na wprowadzane restrykcje w samym systemie operacyjnym (Windows Vista), uniemożliwiające odpluskiwanie aplikacji bez odpowiednich praw, ze względu na możliwość manipulacji na pamięci aplikacji.
1.2.7. Rozpakowywanie aplikacji
Nowoczesne systemy zabezpieczeń aplikacji są w stanie poradzić sobie z różnymi formami ataku na kod aplikacji i czasami jedyną metodą, dzięki której będzie można złamać aplikację jest rozpakowanie zabezpieczonej aplikacji.
Celem tej operacji jest przywrócenie zabezpieczonego pliku aplikacji do oryginalnej postaci (bez zabezpieczeń), dzięki czemu łatwiejsza będzie jego analiza oraz usuwanie dodatkowych zabezpieczeń, jeśli takie zostały zastosowane.
Termin „rozpakowanie” jest tutaj użyty z tego względu iż systemy zabezpieczające (ang. exe-protector) stosują w połączeniu z szyfrowaniem pliku binarnego aplikacji także jego kompresję. Kompresja wykorzystywana jest do zmniejszenia rozmiaru pliku aplikacji po jej zabezpieczeniu, ponieważ zwykle kod zabezpieczenia dodawany do pliku aplikacji zwiększyłby jej rozmiary, a dzięki kompresji możliwe jest zachowanie porównywalnego rozmiaru pliku przed zabezpieczeniem lub nawet uzyskać znaczny stopień kompresji (w zależności od wykorzystanego algorytmu kompresji).
Rozpakowywanie zabezpieczonych aplikacji można podzielić na „ręczne” (ang. manual unpacking) oraz z wykorzystaniem wyspecjalizowanych aplikacji rozpakowujących (ang. unpacker).
Ręczne rozpakowywanie jest procesem pracochłonnym oraz wymagającym znajomości wielu aspektów systemów zabezpieczeń stosowanych w oprogramowaniu. Do ręcznego rozpakowywania zabezpieczonych plików wykorzystuje się całą gamę narzędzi, takich jak debuggery, dezasemblery, programy odbudowujące niektóre elementy plików wykonywalnych, które zostały celowo uszkodzone (ang. rebuilder).
Ręczne rozpakowywanie wymaga dokładnej analizy zabezpieczonego oprogramowania oraz w praktyce prześledzenia całego kodu zabezpieczającego, dzięki czemu możliwe jest poznanie słabych stron zabezpieczenia, co pozwala zrozumieć zasadę jego funkcjonowania oraz umożliwia jego usunięcie.
Wraz z rozwojem zabezpieczeń, narzędzia, takie jak debugger OllyDbg zostały wyposażone w dodatki, pozwalające automatycznie sterować pracą debuggera poprzez języki skryptowe.
Obecnie publikowane są skrypty pozwalające ominąć najpopularniejsze zabezpieczenia (lub ich fragmenty), dzięki czemu odbudowa plików binarnych, zabezpieczonych popularnymi systemami zabezpieczeń staje się w praktyce automatyczna.
Metody te nie zawsze się sprawdzają, głównie ze względu na stopień skomplikowania systemów zabezpieczających (oraz użyte podczas zabezpieczania opcje) lub ich aktualizacje, które często mają na celu powstrzymanie tego typu ataków, jednak automatyzacja procesu usuwania zabezpieczeń pokazuje, że nastąpił znaczący postęp w technikach łamania oprogramowania.
Poniżej zaprezentowany jest przykładowy skrypt, napisany w języku OllyScript przeznaczonym dla debuggera OllyDbg, którego funkcją jest przechwycenie działania wybranej aplikacji w określonym punkcie (w prezentowanym przykładzie chodzi o przechwycenie odszyfrowanych w pamięci danych), a następnie zapisania ich na dysku:
; deklaracja zmiennych
var string_ptr
var file_name
var file_index
var file_size
var x
; ustawianie pułapki (breakpoint) na instrukcji, gdzie
; następuje odszyfrowanie danych
bp 401020
; zainicjalizuj zmienną file_index na 0
mov file_index, 0
; po zastawieniu pułapki, kontynuuj uruchamianie aplikacji
again:
run
; poniższy kod zostanie wykonany jeśli aplikacja natrafiła
; na wcześniej założoną pułapkę, kontynuuj działanie aplikacji
; (bez zatrzymywania się w OllyDbg)
cob
; skrypt pozwala na odczytywanie bieżących rejestrów
; procesora, wskaźnik do odszyfrowanych danych znajduje
; się w pamięci pod adresem wskazanym przez [ebp-14]
mov x, ebp
sub x, 14
mov x, [x]
; zapisz wskaźnik do odszyfrowanych danych do zmiennej
; string_ptr
mov string_ptr, x
; odszyfrowane dane to ciągi znakowe, które zakończone są
; w pamięci bajtem 0x00, znajdując ten bajt, można określić
; rozmiar ciągu znakowego, tak żeby go zapisać na dysk
find string_ptr, #00#
cmp $RESULT, 0
je skip_file
; obslicz rozmiar ciągu znakowego (różnica pomiędzy końcem
; ciągu a jego początkiem
mov x, $RESULT
sub x, string_ptr
mov file_size, x
; przygotuj nazwę pliku, w którym zostanie zapisany
; odszyfrowany ciąg znakowy, zrzucony z pamięci
; funkcja eval działa podobnie jak sprintf z języka C
eval "C:\Test\{file_index}.txt"
mov file_name, $RESULT
; zrzuć pamięć odszyfrowanych danych do pliku
dm string_ptr, file_size, file_name
; wyświetl log z przeprowadzonej operacji w OllyDbg
eval "{file_index} - VA = {string_ptr}, ROZMIAR = {file_size}"
log $RESULT;
; zwiększ indeks używany do tworzenia plików
inc file_index
skip_file:
; kontynuuj działanie aplikacji
jmp againSkładnia języka OllyScript przypomina składnię języka asembler, jednak wyposażony jest on w dodatkowe funkcje, które pozwalają na cały szereg czynności automatyzujących operacje wykonywane ręcznie w debuggerze OllyDbg.
Powyższy przykład stanowi jedynie prostą demonstrację możliwości języka OllyScript, skrypty używane do obchodzenia komercyjnych zabezpieczeń są bardziej rozbudowane, a ich rozmiary dochodzą czasami do kilkudziesięciu kilobajtów kodu.
Oprócz języka OllyScript, istnieje specjalna wersja debuggera OllyDbg o nazwie Immunity Debugger, która wyposażona jest w system skryptowy, oparty na języku Python. Poniżej zaprezentowany jest przykładowy skrypt, wyszukujący określoną instrukcję w podanym module:
#!/usr/bin/env python
__VERSION__ = '1.0'
import immlib
def main():
imm = immlib.Debugger()
cmd="pop ebx"
res=imm.searchCommandsOnModule(0x7C9C1005,cmd)
imm.Log("one module")
for addy in res:
imm.Log( str(addy))
res=imm.searchCommands(cmd)
imm.Log("all modules")
for addy in res:
imm.Log( str(addy) )
if __name__=="__main__":
print "Ten moduł przeznaczony jest dla debuggera Immunity Debugger"Skrypty napisane w języku Python są wykorzystywane najczęściej przy wyszukiwaniu luk w oprogramowaniu, a do łamania zabezpieczeń wykorzystywane są skrypty oparte na języku OllyScript.
Ręczne rozpakowywanie lub z wykorzystaniem skryptów może jednak okazać się zbytnią stratą czasu, gdyż najpopularniejsze systemy zabezpieczeń doczekały się utworzenia narzędzi rozpakowujących, które w prosty sposób pozwalają na odtworzenie oryginalnej postaci zabezpieczonych plików bez jakiejkolwiek dodatkowej ingerencji użytkownika.
Narzędzia te stanowią zwykle połączenie debuggera lub emulatora, pozwalającego na prześledzenie działania kodu zabezpieczającego oraz zrzucenie (ang. dump) na dysk odbezpieczonych fragmentów oryginalnej aplikacji lub ich automatyczną odbudowę.
Często tego typu narzędzia wykorzystują w swoim działaniu specjalnie napisane sterowniki systemowe, aby ukryć swoją obecność przed kodem zabezpieczającym lub obejść zastosowane zabezpieczenia, których nie da się ominąć w trybie użytkownika.
Automatyczne programy rozpakowujące również nie zawsze się sprawdzają, jednak są o wiele groźniejsze, ponieważ dzięki swej prostej obsłudze, mogą być wykorzystywane nawet przez niedoświadczonych użytkowników w celu rozpowszechniania odbezpieczonych kopii oprogramowania.
Rozdział 2. Metody ochrony oprogramowania
W tym rozdziale zostaną szczegółowo omówione metody ochrony oprogramowania przed łamaniem.
2.1. Ochrona przed analizą oprogramowania
Podstawową formą ochrony aplikacji przed analizą jest ukrycie jej kodu przed narzędziami takimi jak dezasemblery oraz debuggery.
Oprócz ukrywania kodu, wykorzystuje się również nowocześniejsze metody, polegające na mutacji oryginalnego kodu, dzięki czemu utrudniona jest jego analiza oraz zrozumienie jego funkcjonowania. Istnieje wiele metod ochrony oprogramowania przed analizą, a omówione poniżej są stosowane w nowoczesnych systemach zabezpieczających.
2.1.1. Kompresja
Kompresja plików binarnych aplikacji była stosowana już w czasach systemu MS-DOS, głównie ze względu na ograniczone rozmiary nośników danych takich jak dyskietki, na których rozprowadzane były programy.
Standardowa dyskietka zaprezentowana poniżej ma pojemność, która w dzisiejszych czasach nie pozwalałaby zapisać jednego pliku MP3, dlatego tak bardzo ceniona była kompresja danych jak i samych aplikacji.

Aplikacje kompresujące wykonywalne pliki binarne nazywane są exe-pakerami (ang. exe-packer). Ich zasada działania podobna jest do zwyczajnych aplikacji archiwizujących dane, z tym wyjątkiem, że do kodu skompresowanego pliku binarnego dodawany jest na końcu mały fragment kodu odpowiedzialnego za dekompresję danych oraz uruchomienie aplikacji.
Jednym z pierwszych popularnych kompresorów dla systemu MS-DOS był polski program autorstwa Piotra Warezaka – WWPack, który pozwalał na kompresję plików binarnych w formatach EXE oraz COM.
Kompresja plików zapewniała jedynie prostą ochronę przed analizą kodu, ponieważ wraz z pojawieniem się narzędzi kompresujących, zaczęły pojawiać się programy, dzięki którym można było rozpakować skompresowane aplikacje.
Jednym z najpopularniejszych programów tego typu był program śledzący (ang. tracer) o nazwie CUP386, dla środowiska DOS, który pozwalał na automatyczne śledzenie skompresowanych plików aplikacji oraz ich automatyczną odbudowę (poprzez zrzucanie obszarów pamięci, które zostały zdekompresowane). Program CUP386 był w stanie automatycznie odbudować aplikacje skompresowane takimi kompresorami jak m.in.:
- WWPack v3.0+ - autor Piotr Warezak
- PkLite - autorstwa PkWare, Inc.
- LzExe – autor Fabrice Bellard
- Diet - autor Teddy Matsumoto
- HackStop v1.15 - autor Rose
Aplikacje kompresujące ewoluowały wraz z nowymi wersjami systemu Windows i do najpopularniejszych można dzisiaj zaliczyć:
- UPX (Ultimate Packer for eXecutables) – obsługujący wiele formatów plików
- FSG (Fast Small Good) – dla 32 bitowych aplikacji (Windows)
- NsPack – dla 32 i 64 bitowych aplikacji (Windows)
- PE-Compact – dla 32 bitowych aplikacji (Windows)
System oparte na Linuxie, oprócz kompresora UPX, nie doczekały się wielu narzędzi kompresujących pliki wykonywalne w formacie Executable and Linkable Format (ELF) i można śmiało stwierdzić, że w tej dziedzinie, wszelkie innowacje były spowodowane rozwojem systemów Windows i często ich niekompatybilnością, co wymuszało na autorach narzędzi kompresujących szukanie rozwiązań dla wielu skomplikowanych problemów technicznych, wynikających z różnic systemowych, choćby pomiędzy systemami operacyjnymi Windows z rodziny 9x oraz systemami opartymi na Windows NT, które różnią się w sposobie ładowania plików wykonywalnych oraz sposobie obsługi niektórych ich struktur.
Obecnie kompresję plików binarnych aplikacji stosuje się jedynie do zmniejszania rozmiarów plików wykonywalnych, nie wykorzystuje się ich do zabezpieczania aplikacji, jednak sama kompresja danych jest wykorzystywana przez systemy zabezpieczające jako dodatek do całości.
Kompresory plików binarnych są także często wykorzystywane do zabezpieczania złośliwego oprogramowania (ang. malware), pozwala to na ominięcie detekcji przez programy antywirusowe, które opierają swoje działanie na skanowaniu plików w poszukiwaniu znanych sygnatur (zestawów bajtów pobranych z rozpowszechnionych wirusów).
Kompresja plików binarnych nie zmienia sposobu ich funkcjonowania, a jedynie powoduje, że oprogramowanie antywirusowe musi być uaktualnione o nowy zestaw sygnatur.
Kompresja złośliwego oprogramowania była także wykorzystywana przeciwko programom antywirusowym, które nie potrafiły sobie poradzić z pokonaniem kodu dekompresującego (wykorzystując do tego celu emulację), jednak obecnie programy antywirusowe są coraz bardziej zaawansowane i wykorzystują inne instrumenty do wykrywania złośliwego oprogramowania, jak np. detekcja behawioralna, bazująca na obserwacji zachowania programów w systemie operacyjnym i zmian przez nich dokonywanych.
2.1.2. Szyfrowanie
Już w czasach systemu MS-DOS oprócz kompresorów plików wykonywalnych, zaczęły pojawiać się bardziej skomplikowane programy, których głównym celem była ochrona oprogramowania przed złamaniem. Programy takie nazywane są exe-protektorami (ang. exe-protector).
Główną różnicą, pomiędzy kompresorami, a protektorami było to, że protektory zawierały oprócz kodu kompresującego, procedury szyfrujące dane oraz takie, które utrudniały odbudowę zabezpieczonej aplikacji do oryginalnej postaci.
Rozwój tego typu oprogramowania zabezpieczającego wiązał się głównie z popularnością programów shareware, które były coraz chętniej zabezpieczane przez ich autorów, aby ustrzec się przed ich złamaniem i w efekcie dostępnością pirackiej wersji na rynku.
Z czasem proste systemy zabezpieczające przeobraziły się w zaawansowane narzędzia, wyposażone w cały szereg metod zabezpieczających, zintegrowane systemy licencyjne, bazujące na infrastrukturze kluczy publicznych (szyfrowanie RSA, krzywe eliptyczne etc.).
Do najpopularniejszych systemów zabezpieczających można zaliczyć:
- PELock
- Asprotect
- Obsidium
- SVKP
- ExeCryptor
- ActiveMARK
- StarForce
Do metod ochrony zastosowanych w systemach zabezpieczających można wymienić m.in. następujące elementy:
- Wykrywanie narzędzi służących do łamania zabezpieczeń
- Szyfrowanie oraz wirtualizacja wybranych fragmentów kodu
- Przebudowa struktur danych aplikacji (tabela importów)
- Ochrona oryginalnych struktur danych aplikacji przed odbudową
- Dynamiczna ochrona pamięci zabezpieczonej aplikacji
- Ochrona przed modyfikacjami plików aplikacji
2.1.3. Wirtualizacja
Wirtualizacja kodu polega na transformacji instrukcji zapisanych w oryginalnej, skompilowanej formie do pseudokodu własnego procesora. Wirtualizacja kodu to obecnie jedna z najpopularniejszych metod stosowanych do utrudnienia zrozumienia działania krytycznych fragmentów kodu, jak np. procedury sprawdzające numery rejestracyjne aplikacji lub jakieś tajne algorytmy przetwarzające dane.
Wirtualizacja kodu sprawia, że analiza kodu wymaga poznania formy instrukcji, do jakich został przetworzony oryginalny kod, analizę maszyny wirtualnej, która odpowiada za interpretację nowych instrukcji oraz na samą analizę kodu poddanego procesowi wirtualizacji, który na dodatek może być jeszcze zmutowany na poziomie pseudokodu.
Sam pomysł wirtualizacji i używanie pseudokodu zamiast kodu asemblera dla jednej platformy nie jest nowy i wykorzystują go języki programowania Java, Visual Basic oraz te z rodziny .NET, czyli C#, VB#, J#, gdzie kod źródłowy kompilowany jest do formy pseudokodu, który uruchomiony, jest interpretowany i wykonywany przez odpowiednią maszynę wirtualną.
Celem zastosowania pseudokodu w przypadku opisanych rozwiązań jest w zamyśle łatwa przenośność skompilowanych aplikacji między różnymi systemami operacyjnymi i procesorami.
Zastosowanie pseudokodu, zamiast kodu odpowiedniego dla zainstalowanego procesora wiąże się ze spadkiem wydajności, ponieważ maszyna wirtualna interpretująca pseudokod jest znacznie wolniejsza niż natywny kod.
W związku z tym, stosuje się kompilację pseudokodu na kod bieżącego procesora (ang. Just In Time compilation, w skrócie JIT). Technika ta pozwala na zastosowanie zaawansowanych algorytmów optymalizacyjnych w zależności od dostępnego procesora i wykorzystanie jego pełnych możliwości z obsługą rozszerzeń takich jak np. rozszerzenia multimedialne procesorów z rodziny x86, czyli MMX, SSE, SSE2 etc.
Dzięki tej technice, aplikacje napisane w językach interpretowanych wykazują się większą wydajnością niż gdyby zostały skompilowane bezpośrednio do kodu wybranego procesora, gdzie kompilowany jest tylko do jednej formy, kompatybilnej w tył ze starszymi procesorami, co zmniejsza jego szybkość.
Wirtualizacja kodu w celu jego zabezpieczenia jest jednak nieco odmienna od opisanych powyżej zastosowań i zwykle wydajność odgrywa tu drugoplanową rolę, za to nacisk nałożony jest na jak największe skomplikowanie maszyny wirtualnej oraz samej formy instrukcji i ich mutację.
Obecnie wirtualizację kodu oferuje większość systemów zabezpieczeń, jak np.:
- StarForce – jest to pakiet zabezpieczający gry komputerowe, który jako pierwszy zastosował transformację kodu wykonywalnego do pseudokodu, dzięki czemu zyskał uznanie wśród wydawców gier, ze względu na wysoki poziom bezpieczeństwa.
- ExeCryptor – pakiet zabezpieczający wszelkiego rodzaju aplikacje komercyjne dla systemów Windows, wykorzystujący jako jedną z technik zabezpieczenia, częściową wirtualizację kodu aplikacji.
- Themida – zaawansowany system zabezpieczający aplikacje dla systemu Windows, który oferuje transformację kodu aplikacji na kod jednego z wybranych wirtualnych procesorów.
- VMProtect – pakiet zabezpieczający aplikacje oraz sterowniki systemowe, który bazuje na transformacji kodu aplikacji na pseudokod.
Wymienione narzędzia nadają się do zabezpieczeń aplikacji dla systemu Windows, napisanych w dowolnym języku programowania, pod warunkiem, że plik wykonywalny zawierać będzie kod kompatybilny z procesorami x86.
W przypadku wymienionych pakietów, wirtualizację stosuje się zwykle do zabezpieczania niewielkiej liczby procedur i funkcji w danej aplikacji, gdyż wiąże się to w opisanym spadkiem wydajności.
Programiści podczas pisania kodu źródłowego aplikacji, najczęściej oznaczają fragmenty kodu specjalnymi markerami, które pozwalają pakietom zabezpieczającym na odnalezienie fragmentów kodu, które mają być poddane procesowi transformacji do pseudokodu.
Przykład oznaczenia kodu do transformacji w aplikacji dla środowiska Delphi:
function Test(i: integer): integer;
begin
// marker oznaczający początek kodu, który ma być
// poddany transformacji do pseudokodu
{$I VM_START.inc}
Result := i * 2;
// marker oznaczający koniec kodu
{$I VM_END.inc}
End;Istnieją jednak o wiele bardziej wyspecjalizowane pakiety zabezpieczające, które pozwalają na tworzenie aplikacji w językach do tego specjalnie zaprojektowanych, które będą w całości skompilowane do pseudokodu, jednak tego typu oprogramowanie stanowi rzadkość.
Wirtualizacja kodu jest i najprawdopodobniej będzie najczęściej stosowaną metodą ochrony oprogramowania przed złamaniem i można oczekiwać, że w tej dziedzinie nastąpi znaczny postęp, ponieważ metoda ta skutecznie utrudnia lub wręcz uniemożliwia zrozumienie zasady działania kodu oraz nie pozwala na jego prostą modyfikację.
2.2. Ochrona przed modyfikacją plików oraz pamięci
Ochrona przed modyfikacjami wprowadzanymi do plików aplikacji lub ich pamięci stanowi kluczowy element ochrony przed złamaniem, gdyż modyfikacja istotnych elementów oprogramowania może być łatwą metodą na ominięcie zastosowanych zabezpieczeń.
2.2.1. Sumy kontrolne
Sumy kontrolne (ang. checksum) są podstawową formą ochrony plików aplikacji, pozwalającą stwierdzić czy oryginalna zawartość została modyfikowana. Sumy kontrolne obliczane są najczęściej z plików skompilowanych programów, a następnie umieszczane w dodatkowych plikach rozprowadzanych z aplikacjami (np. w bazach danych) lub w strukturze samych kontrolowanych plików (w określonej lokalizacji pliku, którą podczas obliczania sumy kontrolnej się pomija).
Podczas uruchamiania aplikacji, obliczana jest suma kontrolna z bieżących danych i porównywana do oryginalnej wartości kontrolnej. Jeśli sumy kontrolne się zgadzają, świadczy to o tym, że nic nie zostało zmodyfikowane, jeśli jednak sumy kontrolne się nie zgadzają, może to świadczyć o świadomej modyfikacji (np. w celu usunięcia zabezpieczenia), dokonanej na plikach aplikacji i zazwyczaj w takich okolicznościach, aplikacja jest zamykana.
Należy tutaj zauważyć, że zmiana sumy kontrolnej wykonywalnego pliku binarnego może być spowodowana również uszkodzeniem nośnika danych (np. w wyniku fizycznego uszkodzenia) lub rzadziej infekcją przez wirus plikowy, co jednak w ostatnich latach jest rzadkością.
Do obliczania sum kontrolnych wykorzystuje się głównie algorytm CRC32, który pozwala obliczyć 32 bitową wartość kontrolną z dowolnego bufora danych. Poniżej prezentowany jest fragment algorytmu CRC32, napisany w języku C.
static const unsigned int table[256] = {
0x00000000,0x77073096,0xEE0E612C,0x990951BA,0x076DC419,
0x706AF48F,0xE963A535,0x9E6495A3,0x0EDB8832,0x79DCB8A4,
0xE0D5E91E,0x97D2D988,0x09B64C2B,0x7EB17CBD,0xE7B82D07,
...
0x2A6F2B94,0xB40BBE37,0xC30C8EA1,0x5A05DF1B,0x2D02EF8D
};
unsigned int crc32(unsigned char *data, unsigned int size, unsigned int crc)
{
while(size > 0)
{
size--;
crc = (((crc >> 8) & 0xFFFFFF) ^ table[(crc ^ *data++) & 0xFF]);
}
return(crc);
}Ze względu na mały rozmiar końcowej wartości kontrolnej, możliwe jest utworzenie dwóch, różnych zestawów danych, dla których suma kontrolna CRC32 będzie taka sama (tzw. kolizja).
Można sobie wyobrazić sytuację, gdy suma kontrolna CRC32 wykorzystywana jest do weryfikacji pliku wykonywalnego, w którym podmienione zostały niektóre bajty, w wyniku czego suma kontrolna nie będzie się zgadzać, ale dopełnienie zawartości pliku odpowiednimi danymi sprawi, że sumy kontrolne będą się zgadzały.
Ze względu na opisaną słabość, stosuje się najczęściej bardziej skomplikowane algorytmy, takie jak funkcje skrótu (ang. hash), które tworzą dłuższe sumy kontrolne, dla których wygenerowanie dwóch zestawów danych, dających taki sam rezultat byłoby procesem bardzo czasochłonnym.
Algorytmy funkcji skrótu:
|
Nazwa algorytmu |
Rok |
Długość skrótu w bitach |
|
MD2 |
1992 |
128 |
|
MD4 |
1990 |
128 |
|
MD5 |
1992 |
128 |
|
SHA-0 |
1993 |
160 |
|
SHA-1 |
1995 |
160 |
|
SHA-2 |
2004 |
224 / 256 / 384 / 512 |
|
RIPEMD |
1996 |
160 |
|
Whirlpool |
2000 |
512 |
Największą słabością sum kontrolnych jest możliwość ich podmiany lub podmiany kodu, który jest odpowiedzialny za ich wyliczenie, dlatego często stosuje się kilka sum kontrolnych, które dodatkowo sprawdzane są nie tylko z głównego pliku aplikacji, ale także za ich obliczenie i weryfikację odpowiadają np. dodatkowe biblioteki dynamiczne dołączone do całej aplikacji.
2.2.2. Monitorowanie pamięci
Zmiany dokonywane w plikach mogą być wykryte poprzez zastosowanie sum kontrolnych, w taki sam sposób może być weryfikowany kod aplikacji, wgrany do pamięci. Do monitorowania pamięci wykorzystuje się najczęściej dodatkowy wątek w uruchomionej aplikacji, który uruchomiony w tle, odpowiedzialny jest za skanowanie wybranych fragmentów kodu aplikacji i weryfikowanie ich poprawności wykorzystując sumy kontrolne.
O ile implementacja sum kontrolnych plików aplikacji jest w miarę prosta do wykonania dla przeciętnego programisty, o tyle utworzenie kodu monitorującego pamięć aplikacji wymaga już szerszej wiedzy z dziedziny analizy oprogramowania, gdyż wymagana jest w tym wypadku wiedza o adresowaniu plików wykonywalnych w pamięci, znajomość położenia fragmentów kodu, które mają być monitorowane oraz dodatkowe aspekty, takie jak przykładowo relokacje, które sprawiają, że sumy kontrolne są za każdym razem inne, w zależności pod jaki obszar pamięci została załadowana aplikacja przez system operacyjny.
2.2.3. Kody korygujące błędy
Kody korygujące błędy (ang. error correction codes) są wykorzystywane do korekty uszkodzonych danych, np. danych transmisyjnych. Wykorzystanie kodów korekcyjnych może mieć również zastosowanie w ochronie oprogramowania, do naprawy celowo zmodyfikowanego kodu aplikacji w pliku oraz w pamięci. Istnieje kilka wersji kodów korygujących:
- Hamming – wykorzystywany do korekcji 1 bitowych uszkodzeń danych
- Redd-Solomon – wykorzystywany do korekcji większej ilości danych
- Turbo – wykorzystywane do korekcji danych przesyłanych drogą satelitarną
Zastosowanie kodów korekcyjnych wiąże się z dołączeniem do oryginalnych danych dodatkowych informacji, dzięki którym będzie możliwa korekta uszkodzonych fragmentów.
Kody korekcyjne nie znalazły powszechnego zastosowania w systemach zabezpieczających ze względu na niską skuteczność działania w przypadku korekcji dużej ilości zmodyfikowanych danych oraz ze względu na łatwiejszą implementację sum kontrolnych, które sprawdzają się lepiej jako element ochrony przed niechcianymi modyfikacjami wprowadzanymi do aplikacji.
2.3. Wykrywanie narzędzi ułatwiających łamanie aplikacji
Wykrywanie narzędzi służących do łamania oprogramowania jest jedną z najpopularniejszych metod ochrony oprogramowania przed złamaniem.
Metody te wykorzystywane są, aby uniemożliwić uruchomienie aplikacji w obecności wybranych narzędzi. Obecnie istnieje cała gama różnych metod pozwalających wykrywać praktycznie wszystkie dostępne aplikacje, które wykorzystywane są w przełamywaniu zabezpieczeń oprogramowania, jednak aplikacje te doczekały się również rozszerzeń lub specjalnych wersji, które nie są wykrywane popularnymi metodami.
Fakt ten obrazuje, że wykrywanie narzędzi do łamania oprogramowania stanowi jedynie pierwszą linię oporu i nie należy opierać całego zabezpieczenia tylko na jednej metodzie ochrony.
2.3.1. Wykrywanie debuggerów
Debuggery wykrywane są różnymi metodami w zależności od ich rodzaju, czyli debuggery systemowe lub działające w trybie użytkownika. Debuggery systemowe wykrywane są najczęściej dzięki sterownikom, z których korzystają lub poprzez dokładne sprawdzenie struktur systemowych, które w obecności debuggera są modyfikowane, aby umożliwić śledzenie aplikacji oraz operacji przez nią wykonywanych.
Poniżej prezentowana jest metoda pozwalająca wykryć debugger SoftICE poprzez sprawdzenie obecności jego załadowanego sterownika w systemie operacyjnym:
//
// funkcja sprawdzająca obecność debuggera SoftICE
// poprzez wykrywanie jego sterownika w pamięci
//
BOOL IsSoftICE()
{
// sprawdź czy można otworzyć sterownik \\.\SICE
if (CreateFile("\\\\.\\SICE",GENERIC_READ,FILE_SHARE_READ \
| FILE_SHARE_WRITE,NULL,OPEN_EXISTING,0,NULL) \
!= INVALID_HANDLE_VALUE)
{
// wykryto sterownik w systemie, zwróć TRUE
return TRUE;
}
// nie wykryto sterownika \\.\SICE
return FALSE;
}Niektóre debuggery systemowe udostępniają nieudokumentowane funkcje dostępne poprzez własny system API, co również wykorzystywane jest do wykrywania ich obecności.
Poniżej zaprezentowana jest
kolejna metoda, pozwalająca wykryć debugger SoftICE poprzez wywołanie
przerwania numer 3, normalnie wykorzystywanego w debuggerach do
zastawiania pułapek w kodzie, ale ze specjalnym zestawem kodów zapisanych w 16
bitowych rejestrach procesora SI oraz DI:
mov si,'FG'
mov di,'JM'
int 3Wykonanie powyższego kodu bez obecności debuggera SoftICE
spowoduje wyjątek w kodzie (który można bezpiecznie wychwycić), jednak w
obecności debuggera nie nastąpi wyjątek, gdyż debugger SoftICE cały czas
kontroluje przerwanie numer 3 i w razie wykrycia specjalnych wartości w
rejestrach procesora, pozwala na kontynuowanie działania aplikacji.
Niektóre metody wykorzystywane do wykrywania debuggerów systemowych bazują na technikach, które są bezpiecznie wykonywane jedynie na określonych systemach operacyjnych (np. wywoływanie przerwań lub dostęp do struktur systemowych) i ich wykonywanie w bardziej restrykcyjnych środowiskach może powodować zawieszanie działania aplikacji.
Do wykrywania debuggerów działających w trybie użytkownika można wykorzystać bardziej kompatybilne metody, jak np. wykrywanie debuggera po nazwie tytułu jego głównego okna lub nazwie jego procesu.
Debuggery działające w trybie użytkownika charakteryzuje fakt, że korzystają one ze wspólnego zestawu funkcji WinApi oraz za ich działanie odpowiada sam system operacyjny, dzięki czemu możliwe jest wykrycie różnych debuggerów poprzez wykorzystanie informacji, jakie zostawia sam system operacyjny.
Poniżej przedstawiony jest fragment kodu w asemblerze, pozwalający wykryć aktywne debuggery, wykorzystujące funkcje odpluskiwania kodu, wbudowane w system Windows:
cmp dword ptr fs:[30h],0 ; czy to system z rodziny NT?
jns _windows_nt
cmp dword ptr fs:[20h],0 ; wykryj debugger dla
jne _wykryto_debugger ; systemów Windows 95, 98, ME
jmp _kontynuuj ; kontynuuj działanie
_windows_nt:
mov eax,dword ptr fs:[30h] ; wskaźnik do struktury
; systemowej PEB
movzx eax,byte ptr [eax+2] ; obecność debuggera jest
or al,al ; oznaczona w strukturze PEB
jne _wykryto_debugger
_kontynuuj:Fragment ten odwołuje się do dwóch struktur systemowych (w zależności od bieżącego systemu operacyjnego), w których oznaczona jest obecność debuggera i na tej podstawie praca aplikacji jest kontynuowana lub przerywana.
Przy okazji wykrywania debuggerów, należy wspomnieć, że obecność debuggera nie zawsze świadczy o złych zamiarach, jednak zdecydowana większość systemów zabezpieczeń, bazujących na wykrywaniu debuggerów, jego obecność traktuje jako próbę przełamania systemu ochrony.
2.3.2. Wykrywanie narzędzi monitorujących system
Narzędzia monitorujące takie jak FileMon czy RegMon mogą być wykrywane poprzez nazwy sterowników, z których korzystają (podobnie jak wykrywane są debuggery systemowe) lub poprzez tytuły ich okien.
BOOL IsRegMon()
{
HWND hWindow = NULL;
hWindow = FindWindowEx(NULL,NULL,NULL,"Registry Monitor - Sysinternals: www.sysinternals.com");
// zwróć TRUE, jeśli znaleziono uchwyt okna
// o podanym tytule lub FALSE jeśli nie
// znaleziono takiego okna
return (hWindow != NULL) ? TRUE : FALSE;
}Metody bazujące na wykrywaniu aplikacji monitorujących poprzez wyszukiwanie ich okien są powszechnie wykorzystywane w zintegrowanych systemach zabezpieczeń, jednak ich skuteczność jest bardzo mała, gdyż osoby zajmujące się łamaniem oprogramowania korzystają ze zmodyfikowanych wersji tego typu aplikacji, gdzie przykładowo tytuł okienka aplikacji monitorującej jest zmieniony w porównaniu do oryginału.
Często metody bazujące na wykrywaniu okna na podstawie dokładnego tytułu aplikacji są zastępowane przez metody bardziej wyrafinowane, jak sprawdzanie położenia oraz rozmiaru charakterystycznych kontrolek w okienkach aplikacji monitorujących (np. położenia przycisków lub pól edycyjnych).
Rozdział 3. Zasada działania programu Zabezpieczającego
W tym rozdziale zostanie zaprezentowana przykładowa aplikacja zabezpieczająca oprogramowanie przed złamaniem.
Do jej utworzenia zostały wykorzystane wybrane techniki, omówione w poprzednich rozdziałach pracy oraz przykładowy system licencyjny bazujący na kluczach licencyjnych, których zawartość jest wykorzystywana do odszyfrowania fragmentów kodu, oznaczonych specjalnymi markerami.
Bez posiadania odpowiedniego klucza licencyjnego, nie ma się dostępu do zaszyfrowanych fragmentów kodu.
Kolejno przedstawione zostaną etapy jej tworzenia oraz funkcjonowania.
3.1. Informacje wstępne
Aplikacja zabezpieczająca oprogramowanie przed złamaniem została napisana w jezyku C++, korzystając ze środowiska Microsoft Visual Studio oraz w języku asembler dla platformy x86. Działanie utworzonej aplikacji można podzielić na trzy etapy, które zostaną szczegółowo omówione.
3.1.1. Interfejs graficzny aplikacji zabezpieczającej
Aplikacja zabezpieczająca została wyposażona w graficzny interfejs użytkownika, składający się z okienka dialogowego, pozwalającego na wybranie pliku wykonywalnego do zabezpieczenia. Całość została oparta na funkcjach WinApi, bez wykorzystania dodatkowych bibliotek.
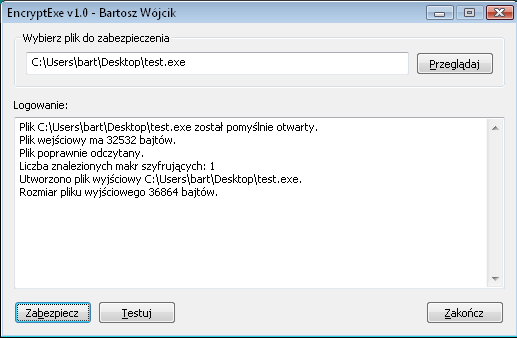
Interfejs graficzny zezwala na wybranie pliku wykonywalnego do zabezpieczenia oraz informuje o kolejnych etapach zabezpieczania pliku. Po zabezpieczeniu pliku, możliwe jest jego szybkie uruchomienie, poprzez wybranie opcji „Testuj”.
3.1.2. Kod programu ładującego
Program ładujący stanowi część aplikacji, która dołączana jest do zabezpieczonego pliku i odpowiada za ochronę oprogramowania przed złamaniem. Kod programu ładującego został utworzony w języku asembler [Wójcik 2004] dla procesorów Intel.
3.1.3. Obsługa struktury plików wykonywalnych
Za obsługę formatu plików wykonywalnych odpowiedzialna
jest klasa CPELib, napisana w języku C++, której głównym zadaniem jest
zapewnienie dostępu do struktur wewnętrznych pliku wykonywalnego oraz
umożliwiająca tworzenie nowych plików wykonywalnych z załączonym kodem
zabezpieczającym.
Do funkcjonowania klasy CPELib została wykorzystana wiedza książkowa z zakresu budowy plików wykonywalnych oraz informacje dostępne w sieci Internet.
3.1.4. Obsługa zabezpieczania plików wykonywalnych
Do obsługi zabezpieczania plików wykonywalnych została użyta
klasa CEncryptExe, która w swoim działaniu wykorzystuje klasę CPELib
oraz kod programu ładującego, aby utworzyć zabezpieczoną kopię oprogramowania.
3.2. Zabezpieczanie pliku wykonywalnego
Klasa CEncryptExe udostępnia metodę EncryptExe,
która odpowiedzialna jest za zabezpieczenie wybranego pliku wykonywalnego.
Jedynym parametrem tej metody jest wskaźnik do struktury opisującej takie
informacje jak ścieżka pliku do zabezpieczenia, ścieżka pliku wyjściowego,
nazwa klucza licencyjnego i inne.
typedef struct _ENCRYPTEXE_PARAMS {
const TCHAR *lpszInputFilename;
const TCHAR *lpszOutputFilename;
ENCRYPTEXE_MSGBOX epMsgLicenseNotFound;
const char *lpszLicenseName;
const char *lpszLicenseKey;
} ENCRYPTEXE_PARAMS, *PENCRYPTEXE_PARAMS;3.2.1. Sprawdzenie parametrów wejściowych
Pierwszym etapem funkcjonowania metody EncryptExe
jest weryfikacja parametrów wejściowych, aby uniknąć błędów w przypadku ich
braku.
DWORD CEncryptExe::EncryptExe(PENCRYPTEXE_PARAMS lpEncryptParams)
{
DWORD dwResult = CEncryptExe::ERR_SUCCESS;
...
/////////////////////////////////////////////////////////////////
//
// sprawdź parametry wejściowe
//
/////////////////////////////////////////////////////////////////
if ( (lpEncryptParams == NULL) || (lpEncryptParams->lpszInputFilename == NULL) )
{
LOG(_T("Proszę podać poprawne parametry wejściowe!"));
return CEncryptExe::ERR_INVALID_PARAMS;
}3.2.2. Dostęp do pliku wejściowego
Kolejnym etapem działania jest uzyskanie dostępu do pliku wejściowego, celem jego późniejszego odczytania.
/////////////////////////////////////////////////////////////////
//
// otwórz plik wejściowy
//
/////////////////////////////////////////////////////////////////
#ifdef UNICODE
hFile = _wfopen(lpEncryptParams->lpszInputFilename, _T("rb") );
#else
hFile = fopen(lpEncryptParams->lpszInputFilename, _T("rb") );
#endif
if (hFile != NULL)
{
LOG(_T("Plik %s został pomyślnie otwarty."), \
lpEncryptParams->lpszInputFilename);
}
else
{
LOG(_T("Nie można otworzyć pliku %s"), \
lpEncryptParams->lpszInputFilename);
return CEncryptExe::ERR_FILE_INPUT;
}Plik wejściowy otwierany jest jako plik binarny w trybie do czytania. Do otwierania pliku zostały wykorzystane funkcje kompatybilne z kodowaniem znaków międzynarodowych w trybie Unicode w zależności od ustawień kompilacji projektu.
Jeśli nie jest możliwe otwarcie pliku (np. gdy
plik jest otwarty już przez inną aplikację), metoda EncryptExe kończy
działanie z odpowiednim kodem błędu, który może być wykorzystany do późniejszej
analizy nieprawidłowego działania.
3.2.3. Odczytanie zawartości pliku
Po uzyskaniu dostępu do pliku, sprawdzany jest jego rozmiar, aby uniknąć sytuacji, w której plik jest pusty, następnie rezerwowany jest obszar pamięci, gdzie wczytywana jest jego zawartość.
/////////////////////////////////////////////////////////////////
//
// sprawdź rozmiar pliku wejściowego
//
/////////////////////////////////////////////////////////////////
fseek(hFile, 0, SEEK_END);
dwFile = ftell(hFile);
fseek(hFile, 0, SEEK_SET);
if (dwFile != 0)
{
LOG(_T("Plik wejściowy ma %lu bajtów."), dwFile);
}
else
{
LOG(_T("Plik wejściowy jest pusty (0 bajtów)!"));
fclose(hFile);
return FALSE;
}
/////////////////////////////////////////////////////////////////
//
// zaalokuj pamięć do odczytania zawartości pliku wejściowego
//
/////////////////////////////////////////////////////////////////
lpFilePtr = new BYTE[dwFile];
if (lpFilePtr == NULL)
{
LOG(_T("Nie można zaalokować pamięci dla pliku wejściowego!"));
fclose(hFile);
return FALSE;
}
/////////////////////////////////////////////////////////////////
//
// odczytaj plik wejściowy
//
/////////////////////////////////////////////////////////////////
if (fread(lpFilePtr, 1, dwFile, hFile) == dwFile)
{
LOG(_T("Plik poprawnie odczytany."));
}
else
{
LOG(_T("Nie można odczytać pliku wejściowego!"));
fclose(hFile);
delete [] lpFilePtr;
return CEncryptExe::ERR_FILE_INPUT_READ;
}
// zamknij uchwyt pliku
fclose(hFile);3.2.4. Wczytanie pliku wykonywalnego
Po odczytaniu zawartości pliku do zaalokowanej pamięci,
jest on kolejno wgrywany poprzez klasę CPELib jako plik wykonywalny,
dzięki czemu uzyskany jest dostęp do jego wewnętrznych struktur i danych.
/////////////////////////////////////////////////////////////////
//
// załaduj plik wejściowy przez klasę CPELib
//
/////////////////////////////////////////////////////////////////
if ( m_PeLib.LoadFile(lpFilePtr, dwFile) != m_PeLib.PERR_SUCCESS)
{
LOG(_T("Plik wejściowy jest niepoprawny (niepoprawny forma Portable Executable)!"));
delete [] lpFilePtr;
return CEncryptExe::ERR_FILE_INPUT_INVALID;
}Podczas wgrywania pliku, korzystając z klasy CPELib,
weryfikowany jest jego format oraz poprawność strukturalna, gdyż zdarzają się
sytuacje, kiedy pliki wykonywalne zawierają uszkodzone lub niepełne dane,
uniemożliwiające dalsze czynności zabezpieczające.
3.2.5. Utworzenie nowego pliku w pamięci
Na podstawie wejściowego pliku, w pamięci tworzona jest jego kopia, zawierająca takie same struktury danych, która będzie wykorzystana do utworzenia zabezpieczonej wersji pliku.
/////////////////////////////////////////////////////////////////
//
// utwórz plik wyjściowy w pamięci, na podstawie pliku
// wejściowego
//
/////////////////////////////////////////////////////////////////
lpRebuilded = m_PeLib.NewFile(lpOepRVA, (m_PeLib.pNT->OptionalHeader.SectionAlignment), (m_PeLib.pNT->OptionalHeader.FileAlignment), FALSE);
if (lpRebuilded == NULL)
{
LOG(_T("Nie można zaalokować pamięci do utworzenia pliku wyjściowego!"));
delete [] lpFilePtr;
return FALSE;
}3.2.6. Suma kontrolna klucza licencyjnego
System licencyjny wykorzystuje system kluczy, bez których nie można odszyfrować fragmentów kodu oryginalnej aplikacji. Do szyfrowania tych fragmentów, użyty jest przykładowy algorytm, który jako klucz stosuje sumę kontrolną, obliczoną z zawartości klucza.
/////////////////////////////////////////////////////////////////
//
// oblicz sumę kontrolną z zawartości klucza licencyjnego,
// będzie wykorzystana przy szyfrowaniu sekcji
//
/////////////////////////////////////////////////////////////////
for (i = 0, dwLicenseKey = 0; i < strlen(lpEncryptParams->lpszLicenseKey); i++)
{
dwLicenseKey += (BYTE)lpEncryptParams->lpszLicenseKey[i];
}Wartość kontrolna wykorzystana jako klucz szyfrujący, stanowi sumę wszystkich bajtów pliku licencyjnego i ma jedynie obrazować mechanizm działania zabezpieczeń stosowanych w gotowych systemach ochrony oprogramowania, gdzie używane są o wiele bardziej skomplikowane schematy weryfikacji i szyfrowania danych licencyjnych.
3.2.7. Szyfrowanie kodu i danych
Kolejnym etapem zabezpieczania pliku jest wyszukiwanie fragmentów kodu, oznaczonych specjalnymi markerami i szyfrowanie kodu znajdującego się pomiędzy nimi kluczem stanowiącym sumę kontrolną pliku licencyjnego. Poniżej zaprezentowany jest przykład umieszczenia markerów szyfrujących w kodzie źródłowym aplikacji:
#include <windows.h>
#include <stdio.h>
#include <conio.h>
#include "EncryptExe.h"
int main()
{
ENCRYPT_START
printf("Klucz licencyjny jest obecny!\n");
ENCRYPT_END
return 0;
}Oprócz szyfrowania oznaczonych fragmentów kodu, szyfrowane są także całe sekcje zawierające kod oraz dane, co ma na celu uniemożliwić łatwe odczytanie zawartości całego pliku osobom postronnym.
/////////////////////////////////////////////////////////////////
//
// - znajdź i zaszyfruj fragmenty kodu pomiędzy markerami
// ENCRYPT_START i ENCRYPT_END
// - dodatkowo zaszyfruj wszystkie sekcje algorytmem RC6
//
// zaalokuj pamięć dla maksymalnej liczby markerów
lpEncryptionMacros = new ENCRYPTEXE_MACRO[ENCRYPTEXE_MACROS_COUNT];
// wygeneruj losowe klucze szyfrujące dla algorytmu RC6
for (i = 0; i < sizeof(cEncryptionKey); i++)
{
cEncryptionKey[i] = (BYTE)rand();
}
for (i = 0, lpCurrentSection = m_PeLib.pSections; i < m_PeLib.dwSections; i++, lpCurrentSection++)
{
bEncrypted = FALSE;
// zaszyfruj tylko sekcje kodu i danych, pozostałe ignoruj
for (j = 0; j < sizeof(szSections) / 4; j++)
{
// czy to poprawna nazwa sekcji pliku wykonywalnego?
if (strncmp((const char *)&lpCurrentSection->Name[0], \
szSections[j], 8) == 0)
{
// sprawdź, czy sekcje zawierają jakieś dane
if ( (lpCurrentSection->VirtualAddress != 0) && \
(lpCurrentSection->SizeOfRawData != 0))
{
// pobierz wskaźnik do danych sekcji w pliku
lpData = m_PeLib.RVA2Offset(lpCurrentSection->VirtualAddress);
dwData = lpCurrentSection->SizeOfRawData;
// odnajdź fragmenty kodu pomiędzy
// markerami ENCRYPT_START i ENCRYPT_END
dwEncryptionMacros += FindEncryptionMacros(lpData, \
lpCurrentSection->VirtualAddress, dwData, \
&lpEncryptionMacros[dwEncryptionMacros]
);
// zaszyfruj całą sekcję
rc6_crypt(cEncryptionKey, lpData, dwData, TRUE);
bEncrypted = TRUE;
}
}
}
// przekopiuj sekcję do nowego pliku wyjściowego
lpSection = m_PeLib.CopySection(lpCurrentSection, FALSE);
// czy sekcja była zaszyfrowana?
if (bEncrypted == TRUE)
{
// ustaw specjalny marker w strukturze sekcji
// informujący program ładujący o zaszyfrowaniu
lpSection->NumberOfLinenumbers = 1;
// dodaj flagi do zapisu do zaszyfrowanej sekcji
lpSection->Characteristics |= IMAGE_SCN_MEM_WRITE;
}
}Zaszyfrowane sekcje kodu i danych są oznaczane w strukturze nagłówka sekcji specjalnym markerem, który podczas uruchamiania zabezpieczonej aplikacji jest odczytywany i jeśli jest ustawiony, cała sekcja jest odszyfrowana.
3.2.8. Dodawanie programu ładującego
Program ładujący jest napisany w języku asembler i jego
zadaniem jest m.in. obsługa zaszyfrowanych fragmentów kodu, weryfikacja danych
licencyjnych oraz wykrywanie narzędzi służących do łamania oprogramowania.
Program ładujący dodawany jest na końcu zabezpieczonego pliku, w nowej sekcji o
nazwie .code.
/////////////////////////////////////////////////////////////////
//
// wstaw kod programu ładującego do zabezpieczonego pliku
// dodaj informacje o zaszyfrowanych fragmentach kodu
//
/////////////////////////////////////////////////////////////////
DWORD dwLoaderCode = sizeof(cLoaderCode) + dwEncryptionMacros * sizeof(ENCRYPTEXE_MACRO);
lpLoaderCode = new BYTE[dwLoaderCode];
memcpy(lpLoaderCode, cLoaderCode, sizeof(cLoaderCode));
memcpy(&lpLoaderCode[sizeof(cLoaderCode)], lpEncryptionMacros, dwEncryptionMacros * sizeof(ENCRYPTEXE_MACRO));
lpCurrentSection = m_PeLib.InsertSection(".code", lpLoaderCode, dwLoaderCode, 0xE00000E0);
delete [] lpEncryptionMacros;
delete [] lpLoaderCode;
lpLoaderCode = m_PeLib.RVA2OffsetNew(lpCurrentSection->VirtualAddress);Po dodaniu programu ładującego należy uaktualnić niektóre jego dane, np. liczbę zaszyfrowanych fragmentów kodu, nazwę szukanego pliku klucza licencyjnego, oryginalny punkt wejściowy kodu zabezpieczonej aplikacji oraz położenie ważnych struktur oryginalnego pliku, które po uruchomieniu muszą być skorygowane przez sam program ładujący.
/////////////////////////////////////////////////////////////////
//
// uaktualnij program ładujący
//
// - ustaw oryginalny adres wejściowy dla aplikacji
// - ustaw adres tabeli importów aplikacji
// - ustaw globalne klucze szyfrujące
// - zapisz liczbę markerów ENCRYPT_START i ENCRYPT_END
//
/////////////////////////////////////////////////////////////////
ReplaceValue(lpLoaderCode, sizeof(cLoaderCode), "OEP1", m_PeLib.pNT->OptionalHeader.AddressOfEntryPoint);
ReplaceValue(lpLoaderCode, sizeof(cLoaderCode), "IAT1", m_PeLib.pNT->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
ReplaceValue(lpLoaderCode, sizeof(cLoaderCode), "MAR1", dwEncryptionMacros);
ReplaceValue(lpLoaderCode, sizeof(cLoaderCode), "MAR2", dwEncryptionMacros);
memcpy(&lpLoaderCode[LDR_ENCRYPTION_KEY], cEncryptionKey, sizeof(cEncryptionKey));
// nazwa pliku klucza licencyjnego
COPY_STRING_TO_LOADER(16, LDR_LICENSE_FILE, lpEncryptParams->lpszLicenseName);
// teksty dla okienka informacyjnego
COPY_STRING_TO_LOADER(128, LDR_MSG_LICENSE_CPT, lpEncryptParams->epMsgLicenseNotFound.lpszMsgCaption);
COPY_STRING_TO_LOADER(128, LDR_MSG_LICENSE_TXT, lpEncryptParams->epMsgLicenseNotFound.lpszMsgText);
SET_LOADER_DWORD(LDR_MSG_LICENSE_ICO, lpEncryptParams->epMsgLicenseNotFound.uType);Program ładujący do działania wykorzystuje funkcje WinApi systemu Windows, aby móc z nich korzystać, do programu ładującego dołączona jest specjalna tabela, nazwana tabelą importów (ang. import table), która zawiera informacje z jakich funkcji systemu Windows program ładujący będzie mógł skorzystać.
Tabela importów programu ładującego za każdym razem umieszczana jest w innym miejscu zabezpieczanego pliku, dlatego niektóre jej elementy wymagają korekty w zależności od jej bieżącego położenia.
/////////////////////////////////////////////////////////////////
//
// uaktualnij tabelę importów programu ładującego
//
/////////////////////////////////////////////////////////////////
lpLoaderImports = (PIMAGE_IMPORT_DESCRIPTOR)lpLoaderCode;
while(lpLoaderImports->OriginalFirstThunk != 0)
{
lpLoaderImports->FirstThunk += lpCurrentSection->VirtualAddress;
lpLoaderImports->OriginalFirstThunk += lpCurrentSection->VirtualAddress;
lpLoaderImports->Name += lpCurrentSection->VirtualAddress;
lpLoaderApis = (PDWORD)m_PeLib.RVA2OffsetNew(lpLoaderImports->OriginalFirstThunk);
while (*lpLoaderApis != 0)
{
*lpLoaderApis += lpCurrentSection->VirtualAddress;
lpLoaderApis++;
}
lpLoaderImports++;
dwLoaderImports += sizeof(IMAGE_IMPORT_DESCRIPTOR);
}Po aktualizacji struktury tabeli importów programu ładującego, jest ona ustawiana jako domyślna tabela importów dla aplikacji, zastępując oryginalną tabelę importów zabezpieczonego pliku:
m_PeLib.SetDirectory(IMAGE_DIRECTORY_ENTRY_IMPORT, lpCurrentSection->VirtualAddress, dwLoaderImports);3.2.9. Ustawienie punktu wejściowego
Po uruchomieniu aplikacji, kontrola przekazywana jest pod adres punktu wejściowego, jest to miejsce, od którego rozpoczyna się działanie aplikacji. W zwyczajnych aplikacjach, adres ten zwykle wskazuje na kod inicjalizujący różne dane, potrzebne do dalszego funkcjonowania programu.
Po zabezpieczeniu pliku, adres wejściowy musi być ustawiony na kod programu ładującego, który dopiero po wykonaniu swojej pracy, przekaże kontrolę do oryginalnego punktu wejściowego aplikacji.
/////////////////////////////////////////////////////////////////
//
// ustaw adres wejściowy aplikacji na kod programu ladującego
//
/////////////////////////////////////////////////////////////////
m_PeLib.pNewNT->OptionalHeader.AddressOfEntryPoint = lpCurrentSection->VirtualAddress + LDR_ENTRY;3.2.10. Finalizacja procesu zabezpieczenia
Po zaszyfrowaniu kodu i danych oraz dodaniu programu ładującego, wykonywany jest kod odpowiedzialny za aktualizację nowo utworzonego pliku wykonywalnego oraz jego zapisanie do pliku wyjściowego (lub nadpisanie pliku wejściowego).
/////////////////////////////////////////////////////////////////
//
// uaktualnij strukturę pliku PE EXE
//
/////////////////////////////////////////////////////////////////
dwRebuilded = m_PeLib.CloseNewFile();
/////////////////////////////////////////////////////////////////
//
// utwórz plik wyjściowy na dysku lub nadpisz plik wejściowy
//
/////////////////////////////////////////////////////////////////
if (lpEncryptParams->lpszOutputFilename != NULL)
{
lpszNewFile = (TCHAR *)lpEncryptParams->lpszOutputFilename;
}
else
{
lpszNewFile = (TCHAR *)lpEncryptParams->lpszInputFilename;
}
#ifdef UNICODE
hFile = _wfopen(lpszNewFile, _T("wb+"));
#else
hFile = fopen(lpszNewFile, _T("wb+"));
#endif
// sprawdź uchwyt pliku
if (hFile != NULL)
{
LOG(_T("Utworzono plik wyjściowy %s."), lpszNewFile);
}
else
{
delete [] lpFilePtr;
delete [] lpRebuilded;
LOG(_T("Nie można utworzyć pliku %s!"), lpszNewFile);
return CEncryptExe::ERR_FILE_OUTPUT_CREATE;
}
///////////////////////////////////////////////////////////////////
//
// zapisz zawartość pliku wyjściowego
//
/////////////////////////////////////////////////////////////////
// zapisz plik wyjściowy
if (fwrite(lpRebuilded, 1, dwRebuilded, hFile) == dwRebuilded)
{
LOG(_T("Rozmiar pliku wyjściowego %lu bajtów."), dwRebuilded);
dwResult = CEncryptExe::ERR_SUCCESS;
}
else
{
LOG(_T("Nie można zapisać do pliku %s!"), lpszNewFile);
dwResult = CEncryptExe::ERR_FILE_OUTPUT_WRITE;
}Po zapisaniu nowo utworzonego pliku, zwalniana jest wcześniej zaalokowana pamięć (aby nie dopuścić do wycieków pamięci) oraz zamykane są otwarte uchwyty plików.
/////////////////////////////////////////////////////////////////
//
// zwolnij pamięć i uchwyt pliku wyjściowego
//
/////////////////////////////////////////////////////////////////
delete [] lpFilePtr;
delete [] lpRebuilded;
fclose(hFile);Jeśli proces zabezpieczania pliku wykonał się bezbłędnie,
zwrócona zostanie wartość ERR_SUCCESS.
/////////////////////////////////////////////////////////////////
//
// ERR_SUCCESS - oznacza sukces, wszystko inne oznacza błąd
//
/////////////////////////////////////////////////////////////////
return dwResult;
}3.3. Program ładujący i jego funkcje
Program ładujący przejmuje kontrolę zaraz po uruchomieniu zabezpieczonego pliku. W kolejnych podpunktach zostaną przedstawione kolejne etapy jego działania.
3.3.1. Inicjalizacja
Po uruchomieniu aplikacji, system operacyjny ustawia stan
rejestrów procesora i przekazuje kontrolę do punktu wejściowego
aplikacji. W przypadku plików wykonywalnych, ważne jest aby stan początkowy
przed skokiem do oryginalnego punktu wejściowego aplikacji był zachowany
jedynie dla rejestru stosu ESP.
W przypadku plików bibliotek dynamicznych, wymagane jest zachowanie dodatkowych rejestrów ESI, EDI,
EBP i EBX z tego względu, że procedura wejściowa dla bibliotek
dynamicznych jest procedurą w konwencji stdcall i rejestry te
przetrzymują ważne informacje, które nie mogą być modyfikowane.
;///////////////////////////////////////////////////////////////
;
; początek programu ładującego, tutaj rozpoczyna
; się działanie zabezpieczonej aplikacji
;
;///////////////////////////////////////////////////////////////
_loader_entrypoint:
;int 3 ; pułapka (dla debuggowania)
push esi ; \
push edi ; > zachowaj krytyczne rejestry
push ebx ; /3.3.2. Adresowanie relatywne
Wprawdzie położenie kodu ładującego jest znane dla zabezpieczanego pliku, jednak pisanie normalnego kodu, który odwołuje się bezpośrednio do komórek pamięci poprzez stałe adresy wymagałoby skorygowanie każdej takiej instrukcji w kodzie programu ładującego.
Posługując się adresowanie relatywnym, względem jakiejś stałej bazy, bardzo ułatwia pisanie kodu, który jest niezależny od miejsca położenia w pamięci. Metoda ta nazwana jest adresowaniem przez „delta offset” i wykorzystywana była pierwotnie w wirusach komputerowych, jednak znalazła powszechne zastosowanie w systemach ochrony oprogramowania.
;///////////////////////////////////////////////////////////////
;
; oblicz relatywny adres, który umożliwi dostęp do danych
;
; tzw. delta offset
;
;///////////////////////////////////////////////////////////////
call _delta
_delta:
mov eax,dword ptr[esp] ; eax = offset _delta
sub esp,-43.3.3. Wspólny interfejs
Program ładujący posiada wiele danych oraz funkcji porozrzucanych po całym kodzie, dla ułatwienia stworzony został wspólny interfejs, oparty na strukturze danych, w której przechowywane są najczęściej wykorzystywane elementy, takie jak np. adresy procedur WinApi:
;///////////////////////////////////////////////////////////////
;
; główny interfejs komunikacyjny programu ładującego
;
;///////////////////////////////////////////////////////////////
LDR_INTERFACE struct
lpDelta dd ? ; delta offset
hModuleBase dd ? ; bieżąca baza programu
lpIAT dd ? ; wskaźnik do tabeli importów loadera
lpcEncryptionKey dd ? ; wskaźnik do klucza szyfrującego
; sekcje RC6
dwLicensePresent dd ? ; czy klucz licencyjny jest obecny
dwLicenseKey dd ? ; suma kontrolna klucza licencyjnego
lpPEHeader dd ? ; nagłówek PE
lpSectionTable dd ? ; tabela sekcji
dwSectionCount dd ? ; liczba sekcji
bWindows9x dd ? ; czy to Windows 9x
bWindowsNT dd ? ; czy to Windows NT
bWindowsVista dd ? ; czy to Windows Vista i wyżej
LDR_INTERFACE endsInterfejs LDR_INTERFACE jest uaktualniany zaraz po
uruchomieniu zabezpieczonej aplikacji.
3.3.4. Wykrywanie systemu operacyjnego
Niektóre elementy zabezpieczenia funkcjonują jedynie
poprawnie na jednym systemie operacyjnym, dlatego program ładujący wykrywa
wersję systemu Windows i zapisuje informacje strukturze interfejsu LDR_INTERFACE.
;///////////////////////////////////////////////////////////////
;
; pobierz informacje o wersji systemu Windows
;
;///////////////////////////////////////////////////////////////
push esi ; LDR_INTERFACE
call _get_os_version ; uaktualnij dane w strukturze
; LDR_INTERFACE3.3.5. Wykrywanie debuggerów
Przed wykonaniem jakichkolwiek czynności, program ładujący wywołuje procedury wykrywające debuggery systemowe oraz te działające w trybie użytkownika. Jeśli debugger zostanie wykryty, zabezpieczona aplikacja jest natychmiastowo zamykana, bez jakiegokolwiek komunikatu ostrzegawczego.
;///////////////////////////////////////////////////////////////
;
; uruchom kod wykrywający debuggery
;
;///////////////////////////////////////////////////////////////
push esi ; LDR_INTERFACE
call _antidebug_detect ; wykryj aktywne debuggery
test eax,eax ; 0 brak, != 0 wykryto debugger
jne _exit ; w razie wykrycia debuggera, zakończ
; działanie aplikacji3.3.6. Klucz licencyjny
System licencyjny bazuje na kluczach, których zawartość używana jest do tworzenia kluczy deszyfrujących fragmenty kodu oznaczone markerami. Kolejny fragment programu ładującego odpowiada za znalezienie klucza licencyjnego w katalogu uruchomionej aplikacji, jego odczytanie i obliczenie sumy kontrolnej, stanowiącej klucz deszyfrujący.
;///////////////////////////////////////////////////////////////
;
; sprawdź obecność pliku z kluczem licencyjnym
;
;///////////////////////////////////////////////////////////////
push esi ; LDR_INTERFACE
call _verify_license ; sprawdź klucz licencyjnyW przypadku braku klucza, zostanie wyświetlony komunikat ostrzegawczy o ograniczonym funkcjonowaniu aplikacji, gdyż bez klucza, zaszyfrowane fragmenty kodu będą niedostępne.
3.3.7. Odszyfrowanie sekcji kodu i danych
Wszystkie sekcje zawierające kod i dane zostały zaszyfrowane podczas zabezpieczania pliku, dlatego następnym krokiem jest ich odszyfrowanie, za co odpowiada poniższe wywołanie:
;///////////////////////////////////////////////////////////////
;
; odszyfruj sekcje kodu i danych (domyślnie zostały zaszyfrowane
; algorytmem RC6)
;
;///////////////////////////////////////////////////////////////
push esi ; LDR_INTERFACE
call _decrypt_sections ; odszyfruj sekcje3.3.8. Obsługa zaszyfrowanych fragmentów kodu
Zaszyfrowane fragmenty kodu są deszyfrowane jedynie w przypadku obecności poprawnego klucza licencyjnego w katalogi z zabezpieczoną aplikacją, aby jednak mogły poprawnie działać muszą być połączone z kodem programu ładującego.
Wykonanie kodu oznaczonego makrem ENCRYPT_START
powoduje tymczasowe odszyfrowanie i przekazanie kontroli do tego fragmentu
kodu. Wykonanie kodu oznaczonego makrem ENRYPT_END powoduje ponowne
zaszyfrowanie bloku pomiędzy tymi dwoma makrami.
Dzięki tej technice, kod zostaje odszyfrowany tylko na chwilę potrzebną do jego wykonania, co znacznie ogranicza możliwość odbudowy kodu tak zabezpieczonej aplikacji. Bez klucza licencyjnego, fragmenty kodu pomiędzy makrami są omijane.
;///////////////////////////////////////////////////////////////
;
; inicjalizuj obsługę makr szyfrujących
;
;///////////////////////////////////////////////////////////////
push esi ; LDR_INTERFACE
call _initialize_markers ; inicjalizacja makr3.3.9. Wypełnienie tabeli importów aplikacji
Oryginalna tabela importów aplikacji, podczas procesu zabezpieczania pliku została zastąpiona tabelą importów dla programu ładującego. Aby aplikacja funkcjonowała poprawnie, należy wypełnić jej własną tabelę importów poprzez załadowanie wszystkich wylistowanych w niej bibliotek oraz pobranie adresów funkcji, z których korzysta aplikacja.
;///////////////////////////////////////////////////////////////
;
; wypełnij oryginalna tabelę importów aplikacji
;
;///////////////////////////////////////////////////////////////
push esi ; LDR_INTERFACE
call _resolve_imports ; wypełnij tabelę importów
test eax,eax ; 0 sukces, != 0 błąd
jne _exit ; jeśli błąd, zakończ działanieJeśli podczas wypełniania oryginalnej tabeli importów
aplikacji wystąpi błąd, oznacza to zwykle, że aplikacja korzysta z funkcji
niedostępnych dla bieżącego systemu operacyjnego, przykładowo korzysta z
funkcji zawartych w systemie Windows Vista, podczas uruchomienia aplikacji w
systemie Windows 2000. W takim wypadku nie można kontynuować działania
aplikacji, bo adresy funkcji WinApi byłyby ustawione na 0 i najprawdopodobniej
aplikacja spowodowałaby wyjątek (błąd).
3.3.10. Powrót do kodu aplikacji
Po wykonaniu wszystkich czynności, odszyfrowaniu sekcji kodu i danych, ustawieniu procedur dla makr szyfrujących, program ładujący przekazuje kontrolę do oryginalnego punktu wejściowego aplikacji
;///////////////////////////////////////////////////////////////
;
; wróć do oryginalnego punktu wejściowego aplikacji
;
;///////////////////////////////////////////////////////////////
mov eax,'1PEO' ; adres punktu wejściowego aplikacji
add eax,[esi].hModuleBase ; dodaj bieżącą bazę w pamięci do adresu
pop ebx ; \
pop edi ; > przywróć stan krytycznych
pop esi ; / rejestrów
jmp eax ; wykonaj skok do punktu wejściowego aplikacji
;///////////////////////////////////////////////////////////////
;
; zakończenie działania aplikacji w przypadku błędu
;
;///////////////////////////////////////////////////////////////
_exit:
push 1 ; kod błędu
call [edi].lp_ExitProcess ; zamknij aplikacjeZakończenie
Celem niniejszej pracy było zaprezentowanie nowoczesnych metod łamania zabezpieczeń stosowanych w oprogramowaniu oraz przedstawienie metod ochrony oprogramowania przed łamaniem.
Efektem końcowym jest przykładowa aplikacja zabezpieczająca oprogramowanie, wykorzystująca omówione zagadnienia. Użyty system licencyjny bazuje na koncepcjach stosowanych w komercyjnych systemach zabezpieczeń i z powodzeniem może być zastosowany do ochrony oprogramowania przed złamaniem.
Struktura utworzonej aplikacji zabezpieczającej opiera się w głównej mierze na kodzie w języku C++, co pozwala na łatwą jego rozbudowę lub całkowite przeniesienie na dowolną platformę z kompilatorem języka C++. Program ładujący, utworzony w asemblerze i zapisany w formie binarnej pozwala na tworzenie niezależnych modułów dla różnych platform i procesorów.
Metody łamania oprogramowania ciągle ewoluują, dlatego ważne jest, aby oprogramowanie zabezpieczające było ciągle udoskonalane. Utworzona aplikacja zabezpieczająca może być dowolnie rozwijana w takich kierunkach jak np. wirtualizacja kodu, ulepszony system licencyjny, bazujący na silnym szyfrowaniu asymetrycznym.
Dodatkowe ulepszenia mogą dotyczyć wsparcia innych formatów plików wykonywalnych, np. dla platformy Linux lub MacOS. Przyszłościowym rozwiązaniem byłoby także wsparcie zabezpieczania dla aplikacji 64 bitowych oraz opartych o platformę .NET.
Literatura
Podczas pisania tej pracy ani razu nie sięgnąłem do żadnej książki, ale mój promotor się upierał, że muszę coś tam dodać, więc poniżej macie listę książek, których nigdy nie czytałem, ani nie kupowałem i parę stronek, żeby się odczepił ;)
- [Błaszczyk 2004] Błaszczyk A.: Win32ASM.Asembler w Windows. wyd. Helion, Gliwice, 2004.
- [Eckel 2008] Eckel B., Flenov M.: C++. Thinking in C++. Edycja polska. C++. Elementarz hakera, wyd. Helion, Gliwice 2008.
- [Eilam 2005] Eilam E.. Reversing: Secrets of Reverse Engineering, wyd. Wiley Publishing, Indianapolis 2005.
- [Ferguson 2004] Ferguson N., Schneier B.: Kryptografia w praktyce, wyd. Helion, Gliwice 2004.
- [Sweeney 2002] Sweeney P.: Error Control Coding: From Theory to Practice, wyd. John Wiley & Sons, Chichester 2002.
- [Karbowski 2005] Karbowski M.: Podstawy kryptografii, wyd. Helion, Gliwice, 2005.
- [Wójcik 2004] Wójcik B.: Kiedy i jak korzystać z asemblera, Software 2.0, 2002 nr 5, str. 20 – 26.
- [WWW1] opis formatu Portable Executable
- http://msdn.microsoft.com/msdnmag/issues/02/02/PE/
- [WWW2] dokumentacja WinApi http://msdn.microsoft.com/
- [WWW3] opis standardu Unicode http://unicode.com
- [WWW4] konwencja wywoływania funkcji WinApi http://msdn.microsoft.com/en-us/library/zxk0tw93.aspx